


反事实样本合成用于鲁棒视觉问答
Long Chen, Xin Yan, Jun Xiao, Hanwang Zhang, Shiliang Pu, and Yueting Zhuang. 2020. Counterfactual samples synthesizing for robust visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). DOI:https://doi.org/10.48550/arXiv.2003.06576.
导图

摘要
- 现今的VQA模型往往只能捕捉到训练集中表面的语言相关性,无法泛化到具有不同答案分布的测试数据集
- 理想的VQA模型需具备的两个特征:
- 视觉可解释性:模型在做出决策时应该依赖于正确的视觉区域 —> 本文中V-CSS 提升视觉可解释性
- 问题敏感性:模型应该对问题中的语言变化敏感 —> 本文中Q-CSS 提升问题敏感性
- 本文提出了一种模型无关的逆事实样本合成训练方案 Counterfactual Sample Synthesizing (CSS),迫使模型关注所有的关键对象和词语
一、引言
1.1 缓解偏差的主流解决方案
仅问题模型是一种基于集成的方法,即不依赖图像,仅通过问题预测答案的模型
仅问题模型:
-
基于对抗的仅问题模型:梯度混合(Gradient Mixing)对抗偏见核心逻辑:通过共享问题编码器的梯度对抗,迫使主模型摆脱语言偏见。
实现细节:
1、共享编码器的双向梯度
- 结构:VQA 主模型(视觉 + 语言)与仅问题模型共享问题编码器 (e_q(Q))
- 对抗目标:
- 主模型最小化交叉熵损失:(\mathcal{L}{vqa} = \text{CE}(P{vqa}(a|I,Q), a))
- 仅问题模型最大化损失(对抗项):(\mathcal{L}_q = \text{CE}(P_q(a|Q), a)),并通过梯度反转(Gradient Reversal Layer)注入主模型
- 总损失:(\mathcal{L} = \mathcal{L}_{vqa} - \lambda \cdot \mathcal{L}_q)(λ 为对抗权重)
2、偏见暴露的微观机制
- 当仅问题模型仅凭问题猜对答案(如 “多少 X”→“2”),其高置信度 (P_q(a|Q)) 会触发对抗惩罚(梯度反向),迫使主模型必须通过视觉验证
- 案例:输入 “苹果是什么颜色”,仅问题模型因训练偏见输出 “红色”(置信度 0.9),主模型若仅依赖语言,对抗损失会惩罚此预测,强制其检查图像中的苹果颜色(可能为绿色)。
3、局限性与论文改进
- 不稳定训练:对抗梯度冲突导致噪声
- CSS 的缓解:Q-CSS 生成 “苹果→[MASK]” 的反事实问题,使仅问题模型输出低置信度(如 0.2),减少对抗噪声
-
基于融合的仅问题模型:答案分布混合(Distribution Mixing)核心逻辑:后期融合主模型与仅问题模型的概率分布,利用偏见作为正则化信号。
实现细节:
-
1、概率融合公式
- 动态权重混合:(\hat{P}(a) = \beta \cdot P_{vqa}(a|I,Q) + (1-\beta) \cdot P_q(a|Q))
- β 通过训练数据学习,默认 β=0.5
- 仅问题模型的高置信度预测(如 “苹果→红色”)视为 “偏见信号”,主模型需用视觉证据(如 “图像无苹果”)降低其权重。
-
2、反事实样本的融合约束
- V-CSS 场景:原图 “苹果→红色”,反事实样本 “无苹果→非红色”(图 2 (b))。仅问题模型对反事实问题仍预测 “红色”(语言偏见),但主模型因视觉缺失输出 “非红色”,融合后以主模型为主(β=0.8),修正偏见。
- Q-CSS 场景:问题 “苹果→[MASK]”,仅问题模型无法预测(分布均匀),融合后主模型依赖视觉
-
3、与 CSS 的协同优化
- 动态答案分配(DA ASS):融合分布 (\hat{P}) 用于生成反事实样本的答案。例如,仅问题模型对 “关键物体存在” 的子图预测 “红色”,反事实样本答案设为 “非红色”。
- 实验验证:LMH+CSS 在 VQA-CP v2 上准确率 58.95%,远超纯融合的 52.45%,证明反事实样本增强了融合的有效性。
-
-
两类 “Mix” 的对比:从公式到实例维度 对抗 Mix(以 AReg 为例) 融合 Mix(以 LMH 为例) 混合层级 特征层(共享编码器的梯度混合) 输出层(概率分布加权) 目标函数 (\mathcal{L} = \mathcal{L}_{vqa} - \lambda \mathcal{L}_q) (\mathcal{L} = \text{CE}(\hat{P}, a)) 偏见利用 视偏见为 “敌人”,反向惩罚 视偏见为 “信号”,动态加权 训练稳定性 低(梯度冲突) 高(后期融合) 反事实增强 需 CSS 生成关键词缺失样本(如 [MASK]) 直接利用 CSS 的动态答案(如非红色) 典型案例 问题 “多少 X”→对抗惩罚 “2” 的预测 问题 “多少 X”→融合视觉计数结果
尽管基于集成的⽅法在 VQA-CP 上的性能占主导地位,但值得注意的是,当前的⽅法未能赋予它们⼀个理想 VQA 模型不可或缺的两个特征:
- 视觉可解释性:模型在做出决策时应该依赖于正确的视觉区域,即正确的理由
- 问题敏感性:模型应该对问题的语⾔变化敏感

1.2 本论文方案
本文提出V-CSS和Q-CSS和动态答案分配机制:
- V-CSS:在原始图片中遮盖关键对象来合成一个反事实图像
- Q-CSS:将问题中的关键词替换为特殊标记[MASK]
- 动态答案分配机制(DA_Ass):正确样本答案为“绿色”,使用改正确样本生成的反事实样本答案为“非绿色”,即对原先正确样本答案加上“非”
- 本文使用原始样本和合成样本一起训练VQA模型,经过大量互补样本的训练后,VQA模型被迫关注关键对象和词语
二、相关工作
2.1 语言偏见
大量研究表明VQA中存在语言偏见,减少语言偏见有两个主要解决方案:
- 平衡数据集以减少偏差
- 创建更多平衡的数据集
- 缺点:1、数据集在一定程度上减少了偏差,但是数据中的统计偏差仍然可以被利用;2、在特意设计的不平衡数据集中模型性能显著下降
- 设计模型减少偏差
- 对于VQA最有效的去偏模型是基于集成的方法
本文提出的CSS训练方案可以无缝集成到基于集成的方法中,以进一步减少偏差
2.2 视觉可解释性
1、早期工作直接将人类注意力作为监督指导模型的 注意力图,然而由于存在强烈的偏差,即使有适当的注意力图,网络的剩余层仍可能忽略视觉信号
注意力图:
在视觉问答(VQA)等深度学习模型中,注意力图(Attention Map)是一种可视化工具,用于展示模型在处理输入数据(如图像、文本等)时,对不同部分的关注程度
在图像处理中的注意力图:
- 原理:以卷积神经网络(CNN)应用于图像为例,模型在处理图像时,并非对图像的所有区域同等对待。注意力机制会为图像的不同区域分配不同的权重。注意力图就是将这些权重以可视化的方式呈现,直观地展示出模型重点关注了图像中的哪些部分来做出决策。比如在一个识别猫的视觉问答任务中,注意力图可能会突出显示猫的面部、爪子等关键部位,表明模型在判断时对这些区域给予了更高的关注度。
- 生成方式:通常是通过对卷积层输出的特征图进行一系列计算得到。例如,对特征图进行全局平均池化操作,将每个特征图压缩成一个值,这些值代表了不同特征通道对整个图像的重要性程度。然后通过全连接层等操作进一步计算,得到与原始图像尺寸相对应的注意力权重分布,进而生成注意力图。
在文本处理中的注意力图:
- 原理:在处理问题文本时,模型同样会使用注意力机制来聚焦于问题的不同词汇。比如在 Transformer 架构中,自注意力机制可以计算每个位置的词与其他所有位置词之间的关联程度。注意力图会展示出模型在生成答案时,对问题中不同词汇的关注强度。例如对于问题 “图片中红色汽车的速度是多少?”,注意力图可能会在 “红色”“汽车”“速度” 等关键词上有较高的关注度。
- 生成方式:Transformer 中的自注意力计算过程会生成注意力分数矩阵,通过对这些分数进行适当的归一化等处理,并映射到文本序列的位置上,就可以得到注意力图,直观呈现模型对不同词汇的关注情况。
作用
- 理解模型决策:帮助研究人员深入了解模型是如何做出决策的,判断模型是否关注到了真正与任务相关的信息,还是被一些无关因素误导。例如,如果在一个识别动物的任务中,注意力图集中在背景而非动物主体上,就说明模型可能存在问题。
- 优化模型性能:通过分析注意力图,研究人员可以发现模型的弱点和不足,进而对模型进行改进。比如,如果发现模型在某些关键区域的注意力分配不合理,可以调整模型结构或训练策略,引导模型更加关注重要信息,从而提升模型性能。
2、⼀些最近的⼯作利⽤GradCAM来获取每个对象对正确答案的私有贡献,并鼓励所有对象贡献的排名与⼈类标注⼀致。不幸的是,这些模型有两个缺点:1)它们需要额外的⼈类标注。2)训练不是端到端。—>本文对物体计算局部贡献灵感来源
GradCAM:
Gradient - weighted Class Activation Mapping(梯度加权类激活映射),是一种用于可视化深度神经网络决策依据的技术,在视觉问答(VQA)等涉及图像的深度学习任务中具有重要应用。
基本原理
- 核心思路:GradCAM 利用最后一个卷积层的特征图和模型预测类别的梯度信息,生成热力图,以突出显示图像中对特定预测结果有重要贡献的区域。简单来说,它通过计算特征图对预测类别的梯度,来衡量每个特征图对最终预测的重要性,进而生成反映图像不同区域重要程度的可视化结果。
- 具体计算过程:假设我们有一个深度神经网络,其最后一个卷积层输出的特征图为 F(大小为 (H \times W \times C),其中 H 和 W 是特征图的高度和宽度,C 是通道数),模型对某一类别 c 的预测分数为 (y^c)。首先,计算预测分数 (y^c) 对特征图 F 的梯度 (\frac{\partial y^c}{\partial F}),然后对该梯度在空间维度(H 和 W)上进行全局平均池化,得到每个通道的重要性权重 (\alpha^c_k)((k = 1, \cdots, C))。接下来,将每个通道的特征图 (F_k) 与对应的权重 (\alpha^c_k) 相乘并求和,得到一个二维的热力图 (L^c_{GradCAM}),即 (L^c_{GradCAM}=\sum_{k = 1}^{C}\alpha^c_kF_k)。最后,对这个热力图进行上采样,使其大小与原始图像相同,并与原始图像叠加,就可以直观地看到图像中哪些区域对模型预测该类别起到了关键作用。
在视觉问答中的应用
- 解释模型决策:在 VQA 任务中,GradCAM 可以帮助理解模型在回答问题时,主要依赖图像中的哪些区域。例如,当回答 “图片中的苹果在哪里?” 这样的问题时,GradCAM 生成的热力图可以显示模型认为与 “苹果” 相关的图像区域,从而判断模型是否正确地关注到了苹果所在位置来做出回答。如果热力图集中在其他物体上,说明模型的决策依据可能存在偏差。
- 发现模型问题:通过观察 GradCAM 生成的热力图,研究人员可以发现模型在处理图像信息时可能存在的问题。比如,模型可能过度关注图像的背景而忽略了主体,或者对某些关键特征的关注不足。针对这些问题,可以进一步调整模型结构、优化训练数据或改进训练方法,以提高模型在 VQA 任务中的性能。
优点
- 通用性:GradCAM 不依赖于特定的网络架构,几乎可以应用于任何基于卷积神经网络的模型,只要能够获取到最后卷积层的特征图和预测类别的梯度信息,这使得它在不同的视觉任务和模型中都具有广泛的适用性。
- 直观性:它以热力图的形式直观地展示了模型的决策依据,研究人员可以非常直观地看到模型在图像中关注的区域,无需复杂的分析过程就能理解模型的行为,为深入研究模型的性能和改进方向提供了便利。
2.3 问题敏感性
如果 VQA系统真正“理解”问题,应该对问题中的语⾔变体敏感。
《Cycle-Consistency for Robust Visual Question Answering》设计了⼀种在两个对偶任务之间的循环⼀致性损失,并利⽤采样噪声⽣成多样化的问题。然⽽,该论文作者只考虑了问题不同改写对鲁棒性的影响。
相⽐之下,CSS还⿎励模型在改变⼀些关键词时感知问题的差异
循环一致性:
基本原理
- 双向映射:传统的 VQA 模型主要是从图像和问题映射到答案,即给定图像 I 和问题 Q,模型预测答案 A,可表示为 (A = f(I, Q))。而循环一致性在此基础上增加了一个反向映射,即从图像 I 和答案 A 生成问题 (Q'),表示为 (Q' = g(I, A))。然后,将生成的问题 (Q') 再次输入到原始的 VQA 模型中得到预测答案 (A'),即 (A' = f(I, Q')) 。
- 一致性要求:循环一致性要求原始答案 A 和再次预测得到的答案 (A') 尽可能相同,即 (A \approx A') 。这种双向的映射和一致性约束形成了一个循环,所以称为循环一致性。从直观上理解,这就像是一个 “闭环” 过程,通过正向和反向的操作,确保模型在不同方向的映射中保持一致性,从而提升模型对输入变化(如问题的不同表述)的鲁棒性。
在视觉问答中的作用
- 增强语言鲁棒性:在 VQA 任务中,不同的人对同一个图像可能会用不同的语言表述来提问,但期望得到相同的答案。通过引入循环一致性,模型需要学习不同表述问题之间的潜在联系,因为它不仅要准确回答问题,还要能根据答案生成合理的问题,并保证再次回答生成的问题时得到一致的答案。这使得模型对问题语言的变化更加鲁棒,例如,对于 “图片里的猫在做什么?” 和 “这张图片中的猫咪正在进行什么活动?” 这样表述不同但语义相近的问题,模型能给出一致且准确的答案。
- 提升模型性能:循环一致性为模型的训练提供了额外的约束和监督信号。在训练过程中,模型不仅要优化正向问答的准确性,还要满足循环一致性的要求,这促使模型学习到更全面、更鲁棒的图像与语言之间的关联表示。实验结果表明,基于循环一致性的方法在标准 VQA 任务以及新构建的用于评估语言鲁棒性的数据集(如 VQA - Rephrasings)上,性能都优于传统的 VQA 模型。
三、方法
3.1 自底向上自顶向下(UpDn)模型
对于每个图像 I,UpDn 使⽤图像编码器 e 输出⼀组对象特征:V = {v_1, ..., v_{n_v}},其中 v_i 是 i-th 的对象特征。对于每个问题 Q,UpDn 使⽤问题编码器 e 输出⼀组词特征:Q = {w_i, ..., w_{n_q}} ,其中 w_i 是 j-th 词特征。然后,将 V 和 Q 都输⼊到模型 f_{vqa} 中,以预测答案分布:
模型 f_{vqa} 通常包含⼀个注意力机制,并使⽤交叉熵损失进⾏训练
3.2 反事实样本合成(CSS)
CSS 包括三个主要步骤:
- 使⽤原始样本(I, Q, a)训练 VQA 模型;
- 通过 V-CSS 合成反事实样本(I^-, Q, a^-)或通过 Q-CSS 合成反事实样本(I, Q^-, a^-);
- 使⽤反事实样本训练 VQA 模型
注意:对于每个训练样本,CSS只使⽤⼀种确定的反事实合成机制,Q-CSS和V-CSS并不同时使用
下图是CSS生产反事实样本的算法图 :
3.2.1 V-CSS
-
初始化对象选择
选出一个较小的对象集I,并假设I中所有物体都可能对回答这个问题很重要。由于缺乏关于每个样本关键对象的标注,本文遵循提取与问答高度相关的对象。具体来说,⾸先使⽤spaCy POS 标签器对问答中的每个词进⾏ POS 标注,并提取问答中的名词。然后,我们计算对象类别 GloVe嵌⼊与提取的名词之间的余弦相似度,I 中所有对象与问答之间的相似度得分表⽰为 SIM。选择具有最高 SIM 得分的|I|个对象作为 I。
-
POS tags
- Part-of-Speech tags(词性标签):自然语言处理(NLP)中的基础标注符号,用于标记文本中每个词语的 “词性类别”,比如名词(n)、动词(v)、形容词(adj)、副词(adv)等
-
spaCy POS tagger
spaCy:一款流行的开源自然语言处理(NLP)库,支持词性标注、实体识别、句法分析等多种功能,广泛用于 Python 生态的 NLP 任务POS tagger:即 “词性标注器”,是实现 “给词语分配 POS tags” 的工具 / 模块
-
GloVe
- Global Vectors for Word Representation(全局词向量):一款经典的 “预训练词嵌入模型”,由斯坦福大学提出。它通过分析大规模文本语料中 “词语的全局共现频率”,将每个词映射为一个固定维度的 “稠密向量”(如 100 维、300 维),使得语义相近的词在向量空间中距离更近(例如 “猫” 和 “狗” 的向量距离,会比 “猫” 和 “电脑” 更近)。
-
-
物体局部贡献计算
计算每个对象对预测真实答案概率的局部贡献。遵循最近的研究,这些研究利⽤修改后的 Grad-CAM来推导每个参与者的局部贡献,我们计算第 i 个对象特征对真实答案 a 的贡献为:
s(a,v_i) = S(P_{vqa}(a), v_i):= (\nabla_{v_i}P_{vqa}(a))^T 1- (s(a, v_i)):表示图像中第i个视觉对象((v_i))对答案a的贡献分数(重要性)
- (P_{vqa}(a)):VQA 模型预测答案为a的概率
- (\nabla_{v_i}P_{vqa}(a)):模型输出概率(P_{vqa}(a))对视觉对象(v_i)的梯度(反映(v_i)变化对答案概率的影响程度)
- 其中 “1” 是与(v_i)同维度的全为 1 的向量,用于将梯度向量压缩为标量
-
关键对象选择(CO_Sel)
在获得I中所有对象的私有贡献分数s(a,v)后,进行排序,选择分数最高的前K个对象作为关键对象集I^+。K对每张图像是一个动态数值,是满足以下等式的最小数值:
η是常量,本文在所有实验中中设置η为0.65,即选择对答案贡献累计超过 65% 的最小数量对象作为关键对象
反事实样本输入I^-是I中I^+的绝对补集,下图3展示了I, I^+, I^-的示例
-
动态答案分配(DA\_Ass)
对于给定的反事实视觉输入I^-和原始问题Q,组成一个新的VQ对(I^-, Q)。为给新VQ对(I^-, Q)分配答案,本文设计了动态答案分配机制。具体来说,首先将另一个VQ对(I^+, Q)输入到VQA模型中,并获取预测答案分布P_{vqa}^+(a)。然后基于P_{vqa}^+(a),选择预测概率最高的前N个答案作为a^+。然后定义a^- := \{a_i|a_i \in a, a_i \notin a^+\}。在一种极端情况下,如果模型准确地预测对了全部VQ对(I^+, Q),即a \in a^+,那么a^- 为空集\empty,即反事实样本的答案候选不包含原始真实答案。这个基本动机是如果现在的模型能够预测出(I^+, Q)真实答案,那么(I^-, Q)的预测值就不应该包含原始的任何真实答案。


3.2.2 Q-CSS
-
单词局部贡献计算
类似于V-CSS,使用以下公式计算第i个词对真实答案a的贡献:
s(a, w_i) = S(P_{vqa}(a), w_i) := (\nabla _{w_i} P_{vqa}(a))^T 1一、公式各符号的含义
先明确公式中每个符号的物理意义(结合 VQA 场景推断):
- (s(a, w_i)):核心输出,可理解为 “词(w_i)与答案a的关联分数”,用于衡量词(w_i)对 VQA 模型预测答案a的重要性。
- (S(P_{vqa}(a), w_i)):对关联分数的定义式,说明这个分数是基于 VQA 模型的答案概率(P_{vqa}(a))和词(w_i)计算的。
- (P_{vqa}(a)):VQA 模型预测 “答案为a” 的概率(例如,模型看到图片和问题后,预测 “猫” 是答案的概率为 0.8)。
- (v_i):词(w_i)的嵌入向量(如 GloVe 嵌入),是将词(w_i)转化为的低维稠密向量(比如 300 维),用于模型计算。
- (\nabla {v_i} P{vqa}(a)):(P_{vqa}(a))对(v_i)的梯度,表示 “当词(w_i)的嵌入向量(v_i)发生微小变化时,答案a的概率(P_{vqa}(a))会如何变化”。梯度的每个维度对应(v_i)某个维度的变化对(P_{vqa}(a))的影响程度。
- ((\cdot)^T):向量的转置操作。
- 1:全为 1 的向量(维度与(v_i)相同,比如 300 维向量中每个元素都是 1)。
二、公式的核心含义
公式整体表示: “词(w_i)与答案a的关联分数(s(a, w_i)),等于‘答案a的概率(P_{vqa}(a))对词(w_i)嵌入向量(v_i)的梯度’与‘全为 1 的向量’的内积”。
更通俗地说: 梯度(\nabla {v_i} P{vqa}(a))描述了 “词(w_i)的嵌入向量每变化一点,答案a的概率会变化多少”—— 梯度越大,说明词(w_i)的嵌入对答案a的概率影响越显著(即词(w_i)与答案a的关联性可能越强)。
而与全为 1 的向量做内积(((\nabla {v_i} P{vqa}(a))^T1)),本质是将梯度向量的所有维度值相加,得到一个标量(单个数字),作为 “词(w_i)对答案a的总体影响分数”。
三、为什么最后是 “全为 1 的向量 1”?
这里的 “1” 是全为 1 的向量,而非数字 1(公式中是向量运算),其作用是:
-
将多维梯度压缩为标量: 梯度(\nabla {v_i} P{vqa}(a))是与(v_i)同维度的向量(比如 300 维),而我们需要的是一个 “单个分数” 来衡量词(w_i)与答案a的关联程度。用全为 1 的向量与梯度做内积,等价于对梯度的所有维度值求和,直接将多维信息压缩为一个标量,方便后续比较不同词的重要性。
-
平等对待嵌入向量的所有维度: 词嵌入向量(v_i)的每个维度都承载了不同的语义信息(比如 “性别”“类别”“大小” 等)。用全为 1 的向量求和,意味着 “平等看待每个维度的梯度贡献”—— 不偏袒任何一个语义维度,综合所有维度的影响来衡量词(w_i)的总体重要性。
如果换成其他向量(比如某维度为 1、其他为 0),则会只关注单个维度的影响,失去了 “综合评估” 的意义;而全为 1 的向量是最直接、无偏的 “求和工具”。
总结
这个公式的核心是用梯度的总和来衡量 “词(w_i)对 VQA 模型预测答案a的重要性”,其中 “全为 1 的向量” 的作用是将多维梯度压缩为一个综合分数,平等考虑词嵌入所有维度的影响,最终得到可直接比较的关联分数(s(a, w_i))。
-
关键词选择(CW_Sel)
首先为每个问题Q提取问题类型词(例如,上面图三中的“什么颜色”)。然后从剩余的句子中选择得分最高的前K个词作为关键词。反事实问题Q^-是将Q中的所有关键词替换为特殊标记[MASK]。与此同时Q^+是把除问题类型词和关键词外的所有词用[MASK]替代。Q, Q^+, Q^- 如上面的图三3所示
-
动态答案分配
这一步骤与V-CSS相同,对于Q-CSS,DA_Ass的输入是(I, Q^+)
四、实验
设置:
本文实验的性能测试在VQA-CP数据集上进行,为保证实验完整性也在VQA v2上进行实验
本文使用多个模型作为基线模型(UpDn、PoE、RUBi、LMH),测试CSS的的性能
4.1 消融实验
4.1.1 V-CSS和Q-CSS的超参数
设置:通过在基于集成模型的 LMH之上构建所有消融实验。
结果:

- V-CSS 中 I 的⼤⼩:不同 I ⼤⼩的影响如图 4(a)所⽰。我们可以观察到,随着|I|的增加,模型的性能逐渐下降
- V-CSS 中关键对象的⼤⼩:不同数量关键对象的掩码影响如图 4(a)所⽰,图 4(a)⽐较了动态 K(公式2)与⼀些固定常数(例如,1,3,5)。从结果中,我们可以观察到动态 K 实现了最佳性能
- Q-CSS中的关键词大小:图 4(b)从结果中我们可以观察到,仅替换⼀个词(即 top-1)就能达到最佳性能
- V-CSS 和 Q-CSS 的⽐例δ:不同δ值的影响如图 4(c)所⽰。从结果中我们可以观察到,当δ=0.5 时,性能最佳1。
4.1.2 架构无关
设置:由于本文所提出的 CSS 是⼀种模型⽆关的训练⽅案,可以⽆缝地集成到不同的 VQA 架构中。为了评估 CSS 在提升不
同⻣⼲⽹络的去偏性能⽅⾯的有效性,本文将 CSS 集成到多个架构中,包括:UpDn 、PoE(专家积)、RUBi 、LMH。特别是,PoE、RUBi、LMH 是基于集成的⽅法。
结果:
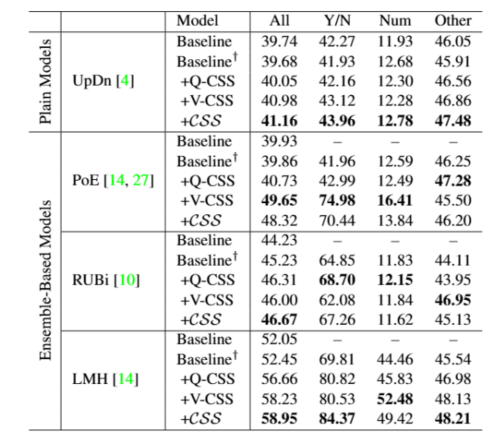
- 与这些基线模型相⽐,CSS 可以持续提高所有架构的性能。在基于集成模型(例如,LMH 和 PoE 中分别提高了6.50%和 9.79%的绝对性能增益)中,这种改进更为显著。
- 此外,当同时使⽤两种类型的 CSS 时,模型通常能达到最佳性能。
4.2 与最先进技术的比较
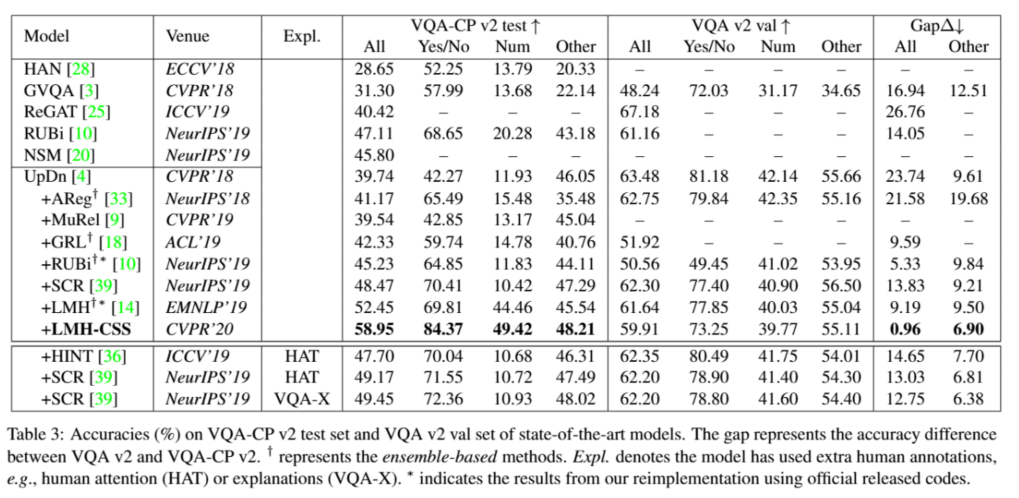
4.2.1 在VQA-CP v2和VQA v2上的性能
设置:
- 本文将 CSS 集成到模型 LMH 中,称为 LMH-CSS,并在 VQA-CP v2 和 VQA v2 上将其与最先进的模型进⾏了⽐较。
- 根据这些模型的⻣⼲⽹络,本文将它们分为以下⼏类:
- AReg、MuRel、GRL、RUBi、SCR、 LMH、 HINT,这些模型使⽤ UpDn 作为其⻣⼲⽹络
- HAN,GVQA,ReGAT,NSM,这些模型使⽤其他不同的⻣⼲⽹络,例如 BLOCK,BAN等
- 特别是AReg,GRL,RUBi,LMH 是集成模型
结果:
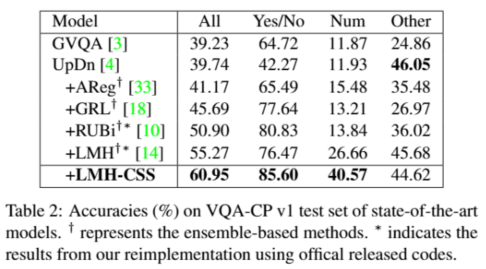
4.2.2 在VQA-CP v1上的性能
设置:
- 进⼀步将 LMH-CSS 与 VQA-CP v1 上的最先进模型进⾏了⽐较
- 同样,我们将这些基线模型分为以下⼏类:
- GVQA 使⽤ SAN作为⻣⼲⽹络
- AReg、GRL、RUBi 和 LMH 使⽤ UpDn 作为⻣⼲⽹络
结果:
4.3 提高视觉可解释能力
本文将通过回答以下问题来验证CSS 提高视觉可解释能力的效果:
- Q1:现有的视觉可解释模型能否被纳⼊基于集成框架?
- Q2:CSS 如何提高了模型的可视化解释能力?
4.3.1 CSS与SCR (Q1)
设置:
- 本文将现有的最先进的可解释视觉模型 SCR集成到 LMH 框架中,并与 CSS 进⾏了⽐较。
- 由于所有最先进的可解释视觉模型(例如,SCR,HINT)的训练都不是端到端的,为了进⾏公平的⽐较,本文使⽤了⼀个训练良好的 LMH(即,在 VQA-CP v2 上达到52.45%的准确率)作为初始模型。
结果:
我们观察到LMH+SCR性能从开始就持续下降,这表明现有的可解释视觉模型不能轻易地集成到基于集成框架中。相⽐之下,CSS 可以提高性能。
SCR:
Jialin Wu 与 Raymond J. Mooney 在 2019 年 NeurIPS(神经信息处理系统大会,AI 领域顶会)发表的论文 《Self-critical reasoning for robust visual question answering》,是鲁棒视觉问答(Robust VQA)领域的经典工作。其核心目标是解决传统 VQA 模型 “依赖数据集偏差(如语言先验)而非真实视觉推理” 的痛点,提出了 “自批判推理(Self-critical Reasoning)” 框架,显著提升了 VQA 模型在分布外数据、对抗样本或偏差场景下的鲁棒性。
一、研究背景:传统 VQA 的核心问题 ——“伪推理” 与鲁棒性缺失
在论文发表前,VQA 模型普遍存在一个关键缺陷:依赖 “表面线索” 而非 “真实视觉 - 语言联合推理”,导致鲁棒性差。具体表现为:
- 语言先验偏差:模型通过训练集统计规律 “投机取巧”,而非看图像。例如,若训练集中 “问颜色时 70% 答案是红色”,模型即使不看图像,遇到 “颜色” 类问题也倾向答 “红色”;
- 分布外泛化差:在与训练集分布不同的数据(如 VQA-CP 数据集,训练 / 测试集的问题 - 答案分布刻意反转)上,准确率大幅下降;
- 对抗脆弱性:对图像或问题的微小扰动(如图像加噪、问题换同义词)敏感,推理逻辑易崩溃。
论文正是针对这一问题,提出 “让模型自我批判推理过程”,强制其依赖视觉证据而非偏差。
二、核心方法:自批判推理(Self-critical Reasoning)框架
论文的核心是设计了一个 **“基础 VQA 模型 + 自批判模块” 的双阶段框架 **,通过 “生成批判信号→修正推理过程” 的循环,让模型学会 “验证答案是否基于视觉事实”。
1. 第一阶段:基础 VQA 模型(Base VQA Model)
- 功能:完成常规 VQA 任务 —— 输入图像(CNN 提取视觉特征,如 ResNet)和问题(LSTM/Transformer 提取语言特征),融合特征后预测答案(如分类式答案或生成式答案)。
- 选择依据:论文未绑定特定基础模型,可适配当时主流架构(如 Bottom-Up & Top-Down、BAN 等),重点是后续的自批判模块对基础模型的修正。
2. 第二阶段:自批判模块(Self-critical Module)
这是论文的核心创新,其核心逻辑是:让模型生成 “批判信号”,检查 “基础模型的答案是否真的由视觉特征支撑”,若依赖偏差则惩罚模型。具体分两步:
- 步骤 1:生成 “反事实样本”(Counterfactual Samples)
为了暴露模型对偏差的依赖,模块会构建 “去除视觉证据” 的反事实场景:
- 图像层面:对原始图像进行 “去语义化处理”(如随机打乱图像块、用灰度图替换原图),破坏视觉特征中的关键信息(如物体、颜色、位置);
- 问题层面:保持问题不变,让基础模型在 “无有效视觉信息” 的反事实图像上重新预测答案。
- 步骤 2:对比推理,生成批判损失(Critical Loss)
模块对比 “原始图像上的答案” 与 “反事实图像上的答案”:
- 若两者一致(如原始图答 “红色”,反事实图也答 “红色”),说明模型未依赖视觉证据,而是靠语言偏差,此时触发高惩罚损失;
- 若两者不一致(如原始图答 “红色”,反事实图答 “无颜色信息”),说明模型依赖了视觉特征,此时触发低惩罚损失。
- 优化目标:将 “基础 VQA 损失(预测答案的分类损失)” 与 “自批判损失” 结合,端到端训练模型,迫使模型在预测时必须 “参考视觉证据”。
三、关键创新点:区别于传统鲁棒 VQA 方法
在此之前,提升 VQA 鲁棒性的方法多集中于 “数据层面”(如平衡训练集偏差、增加对抗样本)或 “损失层面”(如引入偏差惩罚项),而该论文的创新在于:
- “自批判” 机制:不依赖外部数据或人工设计的偏差指标,让模型通过 “自我对比反事实场景” 主动识别偏差依赖,实现 “自主修正推理逻辑”;
- 鲁棒性与性能平衡:传统方法为减少偏差常牺牲标准 VQA 任务的准确率,而该框架在 VQA 2.0(标准数据集)上保持 SOTA 性能的同时,在鲁棒性数据集(如 VQA-CP)上大幅超越基线;
- 通用性:自批判模块可作为 “插件” 适配任意基础 VQA 模型,无需重构核心架构,易用性强。
四、实验验证:鲁棒性显著提升
论文在标准 VQA 数据集(VQA 2.0) 和鲁棒性测试集(VQA-CP v1/v2) 上做了充分验证,核心结果如下:
数据集 核心目标 论文方法 vs 基线提升 VQA 2.0 标准 VQA 任务性能 与当时 SOTA 持平(~72%),无性能损失 VQA-CP v1 测试集偏差反转(鲁棒性) 准确率提升 12.3%(从 51.2%→63.5%) VQA-CP v2 更复杂的偏差反转 准确率提升 9.8%(从 48.7%→58.5%) 此外,论文还通过可视化分析验证了方法的有效性:例如,在 “问颜色” 的问题中,传统模型注意力集中在 “问题中的颜色关键词”,而该方法的注意力集中在 “图像中的颜色区域”(如红色苹果),证明模型确实转向了视觉推理。
五、论文意义与影响
这篇论文是鲁棒 VQA 领域的里程碑工作,其影响体现在:
- 首次将 “自批判推理” 引入 VQA,为 “模型自主修正偏差” 提供了新范式;
- 推动了 VQA 研究从 “追求高准确率” 转向 “追求可靠推理”,后续大量鲁棒 VQA 工作(如反事实 VQA、因果 VQA)均受其启发;
- 验证了 “反事实样本” 在暴露模型缺陷中的价值,为后续对抗训练、分布外泛化研究提供了参考。
总结
该论文针对传统 VQA “伪推理” 的核心痛点,提出了简洁且有效的 “自批判推理” 框架,在不牺牲标准性能的前提下,大幅提升了模型的鲁棒性。其 “让模型自我验证视觉证据” 的思路,不仅解决了当时的鲁棒性问题,也为后续 “可解释 VQA”“因果 VQA” 等方向奠定了基础,是 VQA 领域必读的经典文献之一。
4.3.2 视觉可解释能力评估 (Q2)
设置:本文在定量和定性结果上来评估 CSS 提高视觉可解释能力的效果。
- 对于定量结果,由于缺乏关于每个问题的关键对象的标注,本文将 SIM 分数视为伪真实值。因此,本文设计了⼀个新的指标平均重要性(AI):即具有最高|s(a, v)|的前 K 个对象的平均 SIM 5 分数。
- 对于定性结果,本文在图 5(a)中进⾏了说明。
结果:
定量分析分析:从表4(b)4中,我们可以观察到 CSS 显著提高了 AI 分数,这意味着实际有影响力的对象与问答对的关系更紧密。
定性分析分析:从图 5(a)中,我们可以发现 CSS 帮助模型基于关键对象(即绿⾊框)进⾏预测,并抑制⽆关对象(即红⾊框)的影响。
4.4 提高问题敏感性能力
本文将通过回答以下问题来验证CSS提高问题敏感性能力的效果:
- Q3:CSS 是否有助于提高对问题多样化改写的鲁棒性?
- Q4:CSS 如何提高模型的问题敏感性能力?
4.4.1 对问题改写鲁棒性 (Q3)
设置:
为了更准确地评估鲁棒性,本文使⽤与 VQA-CP 相同的划分⽅式重新拆分了现有的数据集VQARephrasings,并将其命名为 VQA-CP Rephrasings。对于评估,本文使⽤了标准指标⼀致性得分 CS(k)。
一、VQA-Rephrasings 数据集
1. 定义与背景
VQA-Rephrasings 是视觉问答(VQA)领域的鲁棒性评估数据集,由 Shah 等人于 2019 年提出。其核心目标是测试模型对语义等价但表述不同的问题的鲁棒性,解决传统 VQA 模型依赖 “表面语言模式” 而非 “真实语义理解” 的缺陷。例如,给定图像和问题 “how many cookies are on the plate?”,其重述可能为 “what is the number of cookies present on the dish?”,模型需对这类变异保持一致回答。
2. 数据集结构
- 数据来源:基于 VQA v2.0 验证集,随机抽取 40,504 张图像及对应问题,每张图像的每个问题生成 3 个人工重述问题,总计 121,512 个重述问题。
- 标注特点:重述问题通过同义词替换、句式变换、语态转换等方式生成,确保与原问题语义等价但表述不同。例如:
- 原问题:“Is the girl on the horse afraid?”
- 重述问题:“Does the girl seem scared to be riding on the horse?”。
3. 应用场景
- 模型鲁棒性评估:通过对比模型在原始问题与重述问题上的表现,量化其对语言变异的敏感性。
- 训练数据增强:结合重述问题训练模型,提升其泛化能力(如摘要 1 中的对抗训练方法)。
二、指标 CS (k)(Consensus Score)
1. 定义与计算方式
CS (k) 是 VQA-Rephrasings 数据集采用的核心评估指标,用于衡量模型在k 个语义等价问题上的回答一致性。其计算步骤如下:
- 采样子集:对每个原始问题及其 3 个重述问题,随机抽取 k 个问题(k≤4,包含原始问题)。
- 一致性判断:若模型对这 k 个问题的回答均正确,则记为一个 “一致子集”。
- 得分计算:CS (k) = (一致子集数量) / (总采样次数)。
- 例如,当 k=3 时,对每个问题的 4 个版本(1 原 + 3 重述),随机采样 3 个问题,统计所有采样中模型全答对的比例。
2. k 值的意义
- k=1:仅测试模型对单个问题的准确率,与传统 VQA 指标(如 Accuracy)一致。
- k>1:强制模型对语义等价问题保持一致回答,反映其跨语言变异的鲁棒性。例如,k=4 时需模型对原始问题及其所有 3 个重述均正确回答。
- 默认设置:VQA-Rephrasings 中 k 通常取 3 或 4,以平衡计算复杂度与鲁棒性评估粒度。
3. 与传统指标的对比
- 传统指标(如 Accuracy):仅关注单个问题的正确性,无法反映模型对语言变异的鲁棒性。例如,模型可能对原问题回答正确,但对重述问题错误。
- CS(k):通过多问题一致性量化鲁棒性,更贴近真实场景中用户提问的多样性需求。例如,在医疗或工业应用中,模型需对不同表述的同一问题给出一致答案。
三、总结与意义
VQA-Rephrasings 数据集和 CS (k) 指标为 VQA 研究提供了更严格的鲁棒性评估框架,其价值体现在:
- 揭示模型缺陷:通过 CS (k) 可定位模型对特定语言变异的脆弱性(如同义词替换、句式变换)。
- 推动方法创新:促使研究从 “单问题准确率” 转向 “跨问题一致性”,催生循环一致性训练、对比学习等鲁棒性增强技术。
- 应用导向:为医疗、自动驾驶等对可靠性要求高的场景提供了更贴近实际的评估标准。
结果:
从表 4(c)4中,我们可以观察到 Q-CSS 显著提高了对问题多样化改写的鲁棒性。此外,V-CSS 可以帮助进⼀步提高鲁棒性,即 CSS 实现了最佳性能。
4.4.2 问题敏感性能力评估 (Q4)
设置:本文针对定量和定性结果来评估 CSS 在提高问题敏感性能力方⾯的有效性。
-
对于定量结果,由于没有标准评估指标,本文设计了⼀个新的指标置信度提升(CI):给定⼀个测试样本(I,Q,a),我们从问题 Q 中移除⼀个关键名词,得到⼀个新的测试样本(I, Q^*, a)。然后我们将这两个样本输⼊到评估模型中,计算真实答案的置信度下降。
CI = \frac{\sum_{(I, Q)}(P_{vqa}(a|I, Q) - P_{vqa}(a|I, Q^*)) \cdot 1(a = \hat a )}{\sum_{(I, Q)} \cdot 1}$$ , $\hat a$是模型对样本$(I, Q$)预测的答案,1 是一个指示函数
结果:
定性分析结果,我们在图 5(b)5中进行了说明。我们可以发现 CSS 帮助模型基于关键词进行预测(例如,“炉子”或“千层面”),即迫使模型在做出预测之前理解整个问题。
定量分析结果:从表 4(c)4中,我们可以观察到 CSS 帮助模型从关键词中受益更多,即删除关键词会导致对真实答案的信心下降更多。
五、结论
本文提出了⼀种模型⽆关的逆事实样本合成(CSS)训练⽅案,以提高模型的可视化解释能力和问题敏感性。CSS 通过遮蔽关键对象或关键词语来⽣成逆事实训练样本。同时,CSS 可以持续提升不同视觉问答(VQA)模型的表现。最后,本文通过⼴泛的⽐较和消融实验验证了 CSS 的有效性。
 ↩" />
↩" /> ↩
↩  ↩
↩  ↩" />
↩" />
评论区