


Python入门到精通
一、Python安装
1.1 Python
1.2 Anaconda
1.3 Pycharm
二、Python基础
2.1 注释
- 当行注释:# 要注释的内容
- 多行注释:''' 要注释的内容 '''
2.2 关键字与标识符
关键字:Python中内置的一些特定词汇,如:For、While、If、Else、False、True、Finally、Break等
标识符:开发人员为变量、常量函数等起的名称,用做区分
定义标识符注意事项:
- 不能以数字开头
- 区分大小写,如Name和name为两个不同变量
- 不能使用Python内置关键字作为标识符
- 应见名知意,提高可读性
2.3 变量
变量是一种容器,可以装不同类型等待值。变量装的内容可以改变。
变量名称为变量名
变量装的内容为变量值
# 变量赋值(变量第一次出现城变量定义,第二次及之后出现称变量赋值)
变量名 = 变量值
name = ‘张三’
age = 18
gender = ‘M’
2.4 数据类型
2.4.1 数字类型
- 整型(int)
print("整型:" ,type(1))
- 浮点型(float)
print("浮点型",type(3.14))
2.4.2 类型转换函数
| 函数名 | 描述 |
|---|---|
| int(x) | 将对象x转为整型 |
| float(x) | 将对象x转换为浮点型 |
| str(x) | 将对象x转换为字符串类型 |
| tuple(s) | 将序列s转换为元组 |
| list(s) | 将序列s转换为列表 |
| set(s) | 将序列s转换为集合,并对序列s中元素去重 |
2.4.3 布尔类型
注:
Python中布尔类型首字母要大写,True、False
2.5 输入、输出
2.5.1 输入函数(input)
注:
input函数返回的是字符串类型,如果用户输入的是数字,需要使用数字转换函数将输入的字符串类型转换为数字类型
num = input("输入一个数字")
print("num的类型为: ", type(num))
# num是字符串类型
num1 = int(num)
print("num1的类型为: ",type(num1))
2.5.2 输出函数(print)
- 打印变量值
# 一次性打印多个变量
a = 1
b = 2
c = 3
d = 4
print(a,b,c,d)
# 填充打印
name = '张三'
print("name: ", name)
print("name: {name}")
- 换行打印
# 无换行打印
print("hi, this is my world")
print("hi, this is my world", end="")
# 换行打印
print("hi, this is my world", end="/n")
print("hi, this is my world /n")
- 转义字符
print("你好\n世界") #/n被解释为换行
print("你好\\n世界") # 第一个‘\’是转义字符,将后面的字符(在Pyhton中有特殊意义的字符)转换为普通字符
2.6 运算符
2.6.1 算术运算符:+、-、*、/、**、%、//
优先级:幂运算>乘、除、取模、取整>加、减 2+5*2**2 = 22
| 运算符 | 操作 | 解释 |
|---|---|---|
| ** | 1**5=1 | 幂运算 |
| % | 5%2=1 | 模运算(取余运算) |
| // | 5//2=2 | 取整运算 |
2.6.2 比较运算符:==、!=、>、<、>=、<=
2.6.3 逻辑运算符:not、and、or
| 运算符 | 解释 |
|---|---|
| not | 取反 |
| and | 并 |
| or | 或 |
2.6.4 赋值运算符
| 运算符 | 操作 |
|---|---|
| = | a=10 |
| += | a=10,a+=5,则a==15 |
| -= | a=10,a-=5,则a==5 |
| *= | a=10,a*=2,则a==20 |
| /= | a=10,a/=5,则a==2 |
| %= | a=10,a%=3,则a==1 |
| //= | a=10,a//3,则a==3 |
2.6.5 运算符优先级:算数运算符>比较运算符>逻辑运算符
2.7 字符串
2.7.1 字符串格式化
- 使用‘+’号将多个值拼接成字符串
print("a" + "b" + "c")
- 使用格式化符号,实现对字符串的格式化(占位符)
| 运算符 | 描述 |
|---|---|
| %s | 字符串格式化符号 |
| %d | 有符号十进制整数格式化符号 |
| %f | 浮点数格式化符号 |
name = '张三'
print("姓名: %s"%name)
age = 20
print("年龄: %d"%age)
high = 175.6
print("身高: %f"%high)
# 占位输出
print("姓名: %s,年龄: %d, 身高: %f" % (name, age, high))
2.7.2 float类型设置精度输出
# 占位符后面设置精度
high = 178.96
print("身高: %.1f"%high) #结果四舍五入179.0
# format格式化函数
name = "张三"
age = 20
high = 178.4
print("姓名: {}, 年龄: {}, 身高: {:.1f} ".format(name, age, high))
2.7.3 字符串内置方法
| 方法名称 | 使用方法 | 解释 |
|---|---|---|
| find() | str.find(pattern[,start,end]) | 查找子字符串位置。返回pattern子字符串在字符串主字符串start和end范围内的第一个起始下标,不写start、end默认从头开始查找,只填写一个数字默认从数字下标除开始查找。如果没有该子字符串则返回-1 |
| count() | str.count(pattern[,start,count]) | 统计一个字符串包含子字符串的个数 |
| replace() | str.replace(old_pattern,new_pattern[,count]) | 使用新子字符串替换指定的子字符串,count用于指定替换字符串的个数,默认全部替换 |
| split() | str.split(pattern[,maxsplit]) | 返回分割后的字符串列表,按照pattern分割,分割maxsplit次 |
| startswith() | str.startswith(prefix[,start,end]) | 判断字符串在start和end处是否以prefix开头,返回True或False |
| endswith() | str.endswith(suffix[,start,end]) | 判断字符串在start和end处是否以suffix结尾,返回True或False |
| upper()/lower() | str.upper()/str.lower() | 将字符串内容全部转为大写/小写,返回大写/小写字符串 |
| join() | str.join([str1,str2,str3,...]) | 把序列[str1,str2,str3,..]用str连接起来,形成 str1strstr2strstr3str...,如print(','.join("你好","世界")输出"你好*,*世界" |
| strip() | str.strip()/str.strip(",") | strip()默认去掉字符串开头和结尾的空白字符、制表符、换行符.strip(zf)传入参数,去掉字符串前后zf |
2.8 if条件判断
if 表达式1:
pass
elif 表达式2:
pass
else:
pass
2.9 while循环
while 表达式:
pass
# break
# continue
2.10 for循环
for 临时变量 in 序列:
pass
三、容器
3.1 列表
示例:list = ["小明","张三","李四"]
**注:**列表中的元素数据类型可以不同,如list = ["小明", 20, 178.5, 140]
列表是顺序存储的,因此通过索引可以进行随机读取,索引值从0开始
3.1.1 列表定义
list = ["小明","张三","李四"]
3.1.2 列表遍历
# 索引遍历列表
for i in range(0,len(list)):
print(list[i])
# 元素遍历列表
for item in list:
print(item)
3.1.3 列表嵌套
# 把列表作为元素存在另外的一个列表中
info_lists = [["小明", 20, 180.3, True], ["小李", 28, 172.4, False]]
3.1.4 列表添加元素
# 1 append() 向列表末尾添加元素
new_info = ["王五", 21, 178.2, True]
info_lists.append(new_info)
# 2 insert() 向列表指定位置添加元素,insert(索引,元素)
info_lists.insert(1,new_info)
# 3 extend() 向一个列表中添加另外一个列表中的所有元素
an_info_lists = [["小牛", 20, 178.9, False], ["小马", 24, 188.2, True]]
info_lists.extend(an_info_lists)
# 4 使用+号拼接两个列表,组成新的列表
name_list1 = ["小鸡", "小狗"]
name_list2 = ["小牛", "小马"]
name_lists = name_list1 + name_list2
print(name_lists)
3.1.5 列表修改元素
使用索引修改指定位置元素值
3.1.6 列表删除元素
# 1 del 删除列表中指定下标的元素
info_list = ["小王", 30, 123, 42, True]
del info_list[2]
print(info_list)
# 2 remove() 删除列表中与指定的元素值相等的元素
info_list = ["小王", 30, 123, 42, True]
info_list.remove(30)
print(info_list)
# 3 pop() 默认删除列表末尾元素,pop(index)删除索引位置的元素
info_list = ["小王", 30, 123, 42, True]
info_list.pop(1)
print(info_list)
info_list.pop()
print(info_list)
3.1.7 列表切片
# list[] 通过指定起始脚标和结束脚标获取一个子列表
# list[start:end:step] step:步长,默认为1
# 注:切片节区范围是左闭右开,如果设置end值,则需要设置为截取的最后一位的下一位
score_list = [["小牛", 98], ["小狗", 87], ["小猪", 76], ["小羊", 65]]
top2 = score_list[:2] # 索引从0开始,区间左闭右开,截取到索引1,索引end=2
top2_3 = score_list[1:3]
print(top2)
print(top2_3)
3.1.8 列表排序
# sort()默认升序排序
score_list = [10, 20, 21, 13,10]
score_list = [10, 20, 21, 13, 10]
score_list.sort()
print("升序: " + str(score_list))
score_list.sort(reverse=True)
print("降序: " + str(score_list))
3.2 元组
示例: tp = (1,2,3)
元组可以顺序存储相同类型或者不同类型的元素
注:元组一旦被定义,之后不可以修改元组内的元素,元组不支持添加、修改、删除元素操作
3.2.1 元组定义
# 空元组
tp_none = ()
# 仅有一个元素的元组
tp_one = (1,) # 注意:定义只包含一个元素的元组时,在元素的后面要多加一个逗号
3.2.2 查询元组中的元素
# 同列表方式,使用下标进行查询
db_info = ("192.168.0.2", 3306, "root", "password")
ip = db_info[0]
port = db_info[1]
print("ip: {}, port: {}".format(ip,port))
# 遍历元组
for item in db_info:
print(item, end="\t")
3.3 字典
3.3.1 字典的定义
user_info_dict = {"name":"张三", "age":20, "high":178.3, "gender":"male"}
3.3.2 查询字典中键值对
# 通过key获取value
user_info_dict = {"name":"张三", "age":20, "high":178.3, "gender":"male"}
name = user_info_dict["name"]
print(name)
# get()方法
age = user_info_dict.get("age")
print(age)
# 查询不存在的键
tel = user_info_dict.get("tel", "10086") #如果字典中不存在"tel"键则返回默认的值“10086”
3.3.3 向字典中添加键值对
# 通过dict[key] = value的方式向字典中添加键值对
user_info_dict["tel"] = "123456789"
3.3.4 修改字典中键的值
# 通过dict[key] = value的方式向字典中修改键对应的值
user_info_dict["tel"] = "19112341232"
3.3.5 删除字典中的键值对
# del dict[key]
del user_info_dict["tel"]
3.3.6 遍历字典
# 1 通过keys()获取字典中所有key的集合
for key in dict.keys():
print("{}: {}".format(key,dict[key])
# 2 通过values()获取字典中所有的value,但是找不到key
for value in dict.values():
print(value)
# 3 通过items()获取字典中一项,项包括key和valuem, item是一个元组
for item in dict.items():
print(item)
print("key:{}, value:{}".format(item[0],item[1]))
3.4 集合
集合使用类型set表示,用于无序存储相同或不同数据类型的元素
3.4.1 集合的定义
# 集合内存储的值不是键值对,而是一个个独立的值
student_id_set = {"1234", "5678", "1287"}
# 使用set()函数创建集合,set([])接收一个序列作为参数,对序列中的元素去重后创建一个新的集合,序列可以是列表、元组、字符串
student_id_list = ["1234", "2345", "3456","4567","1234"]
student_id_set = set(student_id_list)
# 注:当set()接收字符串为入参时,会把传入的字符串按照字符拆开,每个字符作为个体添加到集合中
string_set = set("hello")
print(string_set)
# 创建空集合
set_none = set()
3.4.2 成员运算符在集合中的应用
# in 或 not in
student_id_set = {"1234", "5678", "1287"}
student_id = "1234"
if student_id in student_id_set:
print("{} 学号存在".format(student_id))
student_id = "1243"
if student_id not in student_id_set:
print("{} 学号不存在".format(student_id))
3.4.3 向集合中添加元素
# 1 add()方法,注:add()方法是要把添加的元素作为整体添加到集合中
student_id_set = {"1234", "5678", "1287"}
student_id = "1204"
print(student_id_set)
student_id_set.add(student_id)
print(student_id_set)
# 2 update()方法,使用update()方法将序列中的每个元素添加到集合中,并对集合中的元素去重。序列可以是列表、元组、集合等
student_id_list = ["0987", "0978", "9876","8765"]
student_id_tp = ("7654", "6543", "5432","4321")
student_id_new_set = {"8273", "9128", "0128"}
# 添加列表
student_id_set.update(student_id_list)
print(student_id_set)
# 添加元组
student_id_set.update(student_id_tp)
print(student_id_set)
# 添加集合
student_id_set.update(student_id_new_set)
print(student_id_set)
# 添加多个序列,序列之间用逗号隔开
student_id_set.update(["1982", "1039"], ["1983", "1029"], ["1984", "1082"])
print(student_id_set)
# 添加字符串
student_id_set.update("00000")
print(student_id_set)
3.4.4 删除集合元素
# 1 remove()方法,使用remove()方法删除集合中指定的元素,若要删除元素不存在,则程序会报错
student_id_set = {"1234", "5678", "1287"}
student_id_set.remove("1234")
print(student_id_set)
student_id_set.remove("1234")
# 2 discard()方法,使用discard方法可以删除集合中指定的元素,如果要删除的元素不存在,也不会引发错误
student_id_set = {"1234", "5678", "1287"}
student_id_set.discard("1234")
print(student_id_set)
student_id_set.discard("1234")
# 3 pop()方法,使用pop方法可以随机删除集合中的某个元素,并返回被删除的元素
item = student_id_set.pop()
print("执行pop方法后: ", student_id_set)
print("被删除的元素: ", item)
3.4.5 集合常用操作
# 交集 两个集合共有的相同元素
# 求两个集合的交集使用集合内置的intersection()方法 或 使用 & 运算符
num_set1 = {1,2,3,4,5}
num_set2 = {1,5,6,7,2}
inter_set1 = num_set1 & num_set2
inter_set2 = num_set1.intersection(num_set2)
print(inter_set1)
print(inter_set2)
# 并集 两个集合包含的所有元素去重组成新的集合
# 求两个集合的并集使用集合内置的union()方法 或 使用 | 运算符
num_set1 = {1,2,3,4,5}
num_set2 = {1,5,6,7,2}
union_set1 = num_set1 | num_set2
union_set2 = num_set1.union(num_set2)
print(union_set1)
print(union_set2)
# 差集 在集合1而不在集合2中的元素
# 求两个集合的差集使用集合内置的difference()方法 或 使用 - 运算符
num_set1 = {1,2,3,4,5}
num_set2 = {1,5,6,7,2}
diff_set1 = num_set1 - num_set2
diff_set2 = num_set1.difference(num_set2)
print(diff_set1)
print(diff_set2)
四、函数
在Python中,函数也是对象,因此函数:
- 可以作为参数被传递
- 可以在函数内部定义
- 可以作为函数返回值
- 函数可以赋值给变量
注:函数作为参数或者返回值的时候不加小括号,加小括号表示调用,不加小括号表示引用
4.1 函数的定义与调用
# python中定义函数的语法格式如下
def 函数名称 (参数):
函数体代码
return 返回值
4.2 函数参数
4.2.1 带参函数
# 带参函数
def print_user_info(name, age , gender):
print("姓名: {}, 年龄: {}, 性别:{}".format(name,age,gender))
print_user_info("张三",20,"男")
4.2.2 缺省参数
# 缺省参数
# 在函数定义时,设置带有默认值的参数叫作缺省参数,调用带有缺省参数的函数时,缺省参数的位置可以不传入实参,如果没有传入缺省参数的值,在函数体内将会使用缺省参数的默认值
def print_user_info(name, age, gender="男"):
print("姓名: {}, 年龄: {}, 性别:{}".format(name,age,gender))
print_user_info("张三",20)
4.2.3 命名参数
# 命名参数
# 命名参数是指在调用带有参数函数时,通过指定参数名称传入参数的值,并且可以不按照函数定义的参数顺序传入实参
def print_user_info(name,age,gender):
print("姓名: {}, 年龄: {}, 性别:{}".format(name,age,gender))
print_user_info(gender="男", name="张三", age=20)
4.2.4 不定长参数
有时需要一个函数能处理不定个数、不定类型的参数,这些参数叫作不定长参数,不定长参数在声明时不会设置所有的参数名称,也不会设置参数的个数
不定长参数有两种定义方式:一种是不定长参数名称前有一个*表示把接收到的参数封装到一个元组中;另一种是不定长参数名称前有两个**表示接收键值对参数,并将接收到的键值对添加到一个字典中
# 带有一个*的不定长参数(计算任意个数数字之和)
def any_num_sum(*args):
print("args参数值: ",args)
print("args参数类型: ", type(args))
sum = 0
for item in args:
sum+= item
return item
any_num_sum(10,20,34)
# 带有两个*的不定长参数(个人工资计算器)
def pay(basic, **kvargs):
print("kvargs 参数值: ",kvargs)
print("kvargs 参数类型: ", kvargs)
tax = kvargs.get("tax")
social = kvargs.get("social")
pay = basic - tax -social
print("实际发放工资: ", pay)
pay(8000, tax=500, social=1500)
# 拆包
# 当一个函数设置了不定长参数,如果像把已存在的元组、列表、字典传入到函数中,并且能够被不定长参数识别,需要使用拆包方法
num_list = [10,20,43,11]
# 由于any_num_sum函数设置了不定长参数*args,所以在传入列表时需要使用拆包方法“*列表”
any_num_sum(*num_list)
fee_dict = {"tax":500, "social":1500}
# 由于pay函数设置了不定长参数**kvargs,所以在传入字典时需要使用拆包方法“**字典"
pay(8000, **fee_dict)
4.3 函数返回值
4.4 变量作用域
变量作用域指的是定义的变量在代码中可以使用的范围,根据变量的适用范围可以将变量分为局部变量和全局变量。
局部变量只能在某个特定的范围内使用,而全局变量可以在全局范围内使用
4.5 递归函数
一个函数在其函数体内调用函数自身,这样的函数就是递归函数。递归函数原理是使用一个函数通过不断地调用函数自身来实现循环处理数据,直到处理到最后一步,再将每一步的计算结果向上一步逐级返回
4.6 匿名函数
在Python中,有一种没有名字的函数,叫作匿名函数。匿名函数不需要使用def关键字,也不需要设置函数名称,在函数定义时,使用lambda关键字声明即可
- 匿名函数语法格式: lambda 参数列表:表达式
- 匿名函数中参数列表的参数数量没有个数限制,多个参数之间用逗号隔开。需要特别注意的是匿名函数会将表达式的计算结果自动返回,不需要使用return关键字
- 匿名函数的用法:可以把匿名函数赋值给一个变量,也可以把匿名函数作为参数传入其他函数中
# 1 将匿名函数赋值给变量,通过变量名调用匿名函数
# 把匿名函数赋值给一个变量
sum = lambda x,y:x+y
# 通过变量名称调用匿名函数
print(sum(10,20))
# 2 匿名函数作为普通函数的参数
def x_y_computer(x,y,func) # func是匿名函数
result = func(x,y) # 对x和y两个参数使用func匿名函数进行计算
print("result = ",result)
x_y_computer(10,20,lambda x,y:x+y)
x_y_computer(10,20,lambda x,y:x*y)
4.7 闭包
闭包指的是当一个嵌套函数的内部函数引用了外部函数的变量,外部函数的返回值是内部函数的引用,这种函数的表达方式称为闭包
# 普通函数,求两个数的和
def sum(x,y):
return x+y
#闭包,求两个数的和
def sum_closure(x):
# 内部函数
def sum_inner(y):
# 调用外部函数的变量x
return x+y
# 外部函数返回值是内部函数的引用
return sum_inner
result1 = sum(10,1) # 结果返回的是数字
func = sum_closure(10) # 结果返回的是函数sum_inner(),func可以当作函数被调用
result3 = func(1) # 结果是数字
4.8 装饰器
类似SpringBoot的切面编程,抽离出与主程序无关的、可复用的代码,使得程序员只需关注核心程序的编写
装饰器使用闭包实现,函数作为实参传入,也可使用"@"符简化编写
- 未使用装饰器
# 模拟客服与客户对话
def contact():
q = inpute("问: ")
print("答: 亲~,对不起,暂时无法回答‘{}’这个问题".format(q))
# 欢迎话术
print("亲~,有什么可以帮助到您的吗?")
# 开始与客户对话
contact()
# 结束话术
print("亲~,请评价一下我的服务!")
print("1 非常满意 2 满意 3 一般 4 差")
score = input("请输入您的评价")
print("感谢您的评价!谢谢")
- 使用闭包,抽离无关代码
def robot(func):
def say():
# 欢迎话术
print("亲~,有什么可以帮助到您的吗?")
# 开始与客户对话
func()
# 结束话术
print("亲~,请评价一下我的服务!")
print("1 非常满意 2 满意 3 一般 4 差")
score = input("请输入您的评价")
print("感谢您的评价!谢谢")
return say
def contact():
q = input("问: ")
print("答: 亲~,对不起,暂时无法回答‘{}’这个问题".format(q))
# 调用闭包函数
func_closure = robot(contact) # 之间传入函数名称
func_closure()
- 使用装饰器
@robot
def contact():
q = input("问: ")
print("答: 亲~,对不起,暂时无法回答‘{}’这个问题".format(q))
# 直接调用contact
contact()
- 装饰器进阶
# 定长参数
# 计算程序执行耗时
def time_counter(func):
def counter(x,y):
start_time = time.time()
print("start_time: ", start_time)
func(x,y)
end_time = time.time()
print("end_time: ",end_time)
print("run times: ",end_time - start_time)
return counter
# 求两个数之和
@time_counter
def sum(x,y):
time.sleep(2)
print("{} + {} = {}".format(x, y, x+y))
# 调用函数
sum(10,20)
# 不定长参数
# 计算程序执行耗时
def time_counter(func):
def counter(*args):
start_time = time.time()
print("start_time: ", start_time)
func(*args)
end_time = time.time()
print("end_time: ",end_time)
print("run times: ",end_time - start_time)
return counter
# 求两个数之和
@time_counter
def sum(x,y):
time.sleep(2)
print("{} + {} = {}".format(x, y, x+y))
# 求三个数字的乘积
@time_counter
def multiplied(x,y,z):
time.sleep(2)
print("{} * {} * {} = {}".format(x, y, z, x*y*z))
# 调用函数
sum(10,20)
multiplied(1,2,3)
五、包和模块
5.1 包
Python包与普通文件夹的区别是,在包内要创建一个"init.py"文件,来标识它不是一个普通文件夹,而是一个包。
一个项目可以包含多个包,一个包可以包含多个子包,也可以包含多个模块。
5.2 模块
一个模块就是一个以".py"结尾的Python文件
不同包下可以有相同名称的模块,模块之间使用"包名.模块名"的方式区分。
以下是在一个模块中引入其他模块的方式:
| 描述 | 引入方法 |
|---|---|
| 引入单个模块 | import package_name.model_name |
| 引入多个模块 | import package_name.model_name1,package_name.model_name2,... |
| 引入模块中的指定函数或类等 | from package_name.model_name import func1,func2,... /from package_name.model_name import class1,... |
| 引入所有模块 | import package_name.* |
5.3 __init__.py模块
在Pthon包中一个包必须包含一个默认的__init__.py模块,当一个包或包下的模块在其他地方被导入时,__init__.py会被Python解释器自动调用执行。
__init__.py的作用:模块内可以说空白内容用于标识一个包,也可以在模块内定义关于包和模块相关的一些初始化操作
注:__init__.py模块的内容会先去该模块其他函数先执行
5.4 __name__变量
__name__变量在不同的运行情况下有不同的值:直接运行本模块,__name__变量被赋值为"__main__",若该模块本其他模块引用时,__name__变量被赋值为模块名称
如果一个Python源码文件既要作为模块在其他地方被引用,又要在其单独运行时执行一些代码,就要在Python源码文件中加入if __name__ == "__main__"的条件判断,也可以把条件判断的这段代码作为Python源码文件的入口
六、面向对象
6.1 面向对象编程(OOP)
Object Oriented Programming是一种解决软件复用的设计和编程方法
6.2 类和对象
6.2.1 类
类(Class)由类名、属性、方法三部分构成
类的定义:
class 类名:
def 方法名(self[,参数列表]):
方法体
注意事项:
- 定义类时首先使用class关键字声明这是一个类,类目遵循标识符的命名规则,类的命名方式通常按“大驼峰”命名法,即组成类名的一个或者多个单词首字母大写,如定义电动汽车类: class ElectricCar
- 在类内部定义的函数叫作方法,在方法中第一个参数默认要传入一个self,标识对象自身,因为根据一个类可以创建多个对象,当调用一个对象的方法时,对象会将自身的引用(指针)传递到调用的方法中,这样Python解释器就知道应该操作哪个对象的方法。注意:定义方法时,self必须作为第一个参数;通过对象调用方法时,不需要显示的在方法中传入self参数,Python解释器会自动传入。
6.2.2 对象
根据类名创建对象的方法:
变量 = 类名([参数列表])
class Person():
def defName(self,name):
self.name = name
xiaoming = Person()
zhangsan = Person()
print("xiaoming的内存地址: {}, zhansan的内存地址: {}".format(id(xiaoming), id(zhangsan)))
3.2.3 __init__构造方法
构造方法的作用是在创建一个类的对象时,对对象进行初始化操作。在创建对象时__init__构造方法会被Python程序自动调用。
如果在定义类时没有显示定义__init__构造方法,在创建对象时程序会自动调用默认没有参数的__init__构造方法。
# 无参构造函数
class Dog:
# 构造方法
def __init__(self):
print("正在执行构造方法,初始化对象")
def eat(self):
print("吃骨头")
def run(self):
print("跑步")
# 创建对象
wangcai = Dog()
wangcai.eat()
wangcai.run()
对象创建过程:
1、首先先在内存中开辟一块内存区域存储创建的对象
2、自动调用__init__构造方法,将该对象的引用作为self参数值传入构造方法,在构造方法内通过self就可以获取对象本身,然后对该对象进行初始化操作
3、初始化操作完成后,将对象的引用返回给变量wangcai,此时变量wangcai指向内存中的对象
# 有参构造函数
class Dog:
# 构造方法
def __init__(self):
print("正在执行构造方法,初始化对象")
# 有参构造方法
def __init__(self, name, gender, age):
print("开始执行有参构造方法")
self.name = name
self.age = age
self.gender = gender
print("初始化完成")
def eat(self):
print("吃骨头")
def run(self):
print("跑步")
# 创建对象
wangcai = Dog() # 隐式创建
wangcai.eat()
wangcai.run()
wangwang = Dog("汪汪","公", 2)
print("小狗名字:{},性别: {},年龄: {} ".format(wangwang.name, wangwang.gender, wangwang.age))
6.4 访问权限
在Python中,类的属性和方法的访问权限不需要任何关键字修饰,只需要在属性或者方法名前面添加两个下划线"__"即为私有的访问权限,反之都是公共访问权限。具有私有访问权限的属性和方法只能在类内部访问,外部不能访问。
class Dog:
# 构造方法
def __init__(self):
print("正在执行构造方法,初始化对象")
# 有参构造方法
def __init__(self, name, gender, age):
print("开始执行有参构造方法")
self.name = name
self.__age = age # 私有属性
self.gender = gender
print("初始化完成")
def __showAge(self): # 私有方法
print("这只狗的年龄为: ",self.age)
6.5 继承
面向对象编程带来的好处之一是代码重用,通过继承机制可以很好地实现代码重用。在程序中继承描述了不同类之间、类型与子类型的关系。
6.5.1 单继承
单继承就是子类只继承自一个父类
单继承类定义格式:class Son(Father)
单继承特点:
- 子类只继承自一个父类,在定义子类时,子类类名后添加一个小括号,小括号中填写父类的类名
- 子类只会继承父类的非私有属性和非私有方法
- 如果在子类中没有定义__init__构造方法,那么在子类创建对象时会自动调用父类的__init__构造方法。如果子类中定义了__init__方法,则不会再调用父类的__init__方法。
6.5.2 super函数
在子类中需要调用父类的方法,有两种方法可以实现
- 方法一、通过“父类名.方法名(self,[参数列表])”的方式调用父类方法,注意:在调用父类方法时需要传入self参数,这个self不是父类的实例对象,而是使用子类的实例对象替代
- 方法二、通过“super().方法名”的方式,不需要显示指定要调用哪个父类的方法,super函数会自动找到要调用的父类方法
6.5.3 重写
重写就是在子类中定义与父类同名的方法。当调用子类对象重写之后的方法时,只会调用在子类中重写的方法,不会调用父类同名的方法。
重写的作用:狗类继承动物类,狗类继承了父类的奔跑行为,但是狗类奔跑起来具有自己的特色,所以狗类通过重写父类动物类的奔跑方法,实现具有自己特色的奔跑方法。
6.5.4 多继承
python3中object类是所有类的基类,其他所有的类都是由object类派生而来的,我们在程序中定义的类都默认继承自object类,只是在定义类时不需要显示写出继承自object类。
多继承是一个子类可以继承多个父类
多继承的定义方式:在类名后的括号中添加需要继承的多个类名,不同的父类之间用逗号隔开
在多继承中,如果不同的父类具有同名的方法,当子类对象未指定调用哪个父类的同名方法时,那么查找调用方法的顺序是:在小括号内继承的多个父类中,按照从左到右的顺序查找父类的方法,第一个成功匹配方法名的父类方法将会被调用。
# 计算机学科
class Computer:
def learnComputer():
print("计算机学生学习计算机")
def selfLearn():
print("自学Python")
# 管理学
class Manager:
def learnManagerment():
print("管理学学生学习管理学")
def selfLearn():
print("自学经济法学")
# 双学位
class DoubleDegree(computer,manager):
def getDegree():
print("获得双学位")
dg = DoubleDegree()
dg.learnComputer()
#__mro__属性可以查看方法、属性解析(搜索)顺序
print(DoubleDegree.__mro__)
dg.selfLearn()
dg.getDegree()
七、异常处理
程序执行的过程中经常会遇到由于代码问题、网络问题、数据问题等各种原因引起的程序运行错误,导致程序崩溃的情况发生。在程序开发的过程中,如果能够提前针对有可能发生的异常进行预处理,做到防患于未然,降低程序崩溃的风险,那么我们的程序将更加的健壮和稳定。对程序中可能发生的异常进行预处理的过程就是异常处理,当程序出现异常,,捕获异常,并进行特定的处理,这样就不会导致程序崩溃,能够稳定运行。
7.1 捕获异常
捕获异常语法格式如下:
try:
可能产业异常的代码块
except ExceptionType as err: # 如果异常类型名称比较长或者拼写比较复杂,不方便在异常处理时使用,可以使用as关键字对异常类型名称重命名
异常处理
# 文件未发现异常
print("准备打开一个文件")
try:
open("test.txt")
print("打开文件成功")
except FileNotFoundError as err:
print("捕获到了异常,文件不存在!", err)
print("程序即将结束")
出现异常后程序立即停止,出现异常之后的代码不执行,转而执行异常处理,处理完异常后继续执行try...except之后的代码
7.2 捕获多个异常
在程序运行过程中可能发生的异常不止一个,所有有时需要捕获多个异常
捕获多个异常的语法格式如下:
try:
可能产生异常的代码块
except (ExceptionType1,ExceptionType2,...) as err:
异常处理
要使用try...except捕获多个异常,只需要把要捕获的异常的类名存储到except的元组中。在程序运行过程中只要元组中列举的任何一个异常,都会被捕获并进行处理。还可以使用as关键字对可能发生的异常重命名
try:
# 打印一个不存在的变量,将产生NameError异常
print(num)
# 读取一个不存在的文件,将产生FileNotFoundError异常
open("text.txt")
except (NameError, FileNotFoundError) as err:
print("捕获到了异常", err)
print("程序即将结束")
7.3 捕获全部异常
在代码中我们可以提前对代码可能产生的异常采取措施,及时捕获和处理,相当于设置了预案,但是有时不可能所有的异常都能够提前被预测到,Python提供了通过捕获Exception异常类可将没有预测到的异常全部捕获
Exception类是所有异常的超集,代表所有异常(超集:一个集合包含另一个集合的所有元素)
try:
# 打印一个不存在的变量,将产生NameError异常
print(num)
# 读取一个不存在的文件,将产生FileNotFoundError异常
open("text.txt")
except FileNotFoundErroras as err: # 只捕获FileNotFoundError,没有捕获NameError
print("捕获到了异常", err)
except Exception as all_err:
print("捕获到全部异常," all_err)
print("程序即将结束")
7.4 异常中的 finally 语句
在程序中,如果一段代码必须要执行,即无论异常是否产生都要执行,那么此时就需要使用finally语句。比如在数据库操作过程中发生异常,但最后仍需要把数据库连接返给连接池,这种情况就需要使用finally语句。
- 产生异常,并捕获异常,最后执行finally中的代码语句
try:
# 打印一个不存在的变量,将产生NameError异常
print(num)
# 读取一个不存在的文件,将产生FileNotFoundError异常
open("text.txt")
except FileNotFoundErroras as err: # 只捕获FileNotFoundError,没有捕获NameError
print("捕获到了异常", err)
except Exception as all_err:
print("捕获到全部异常," all_err)
finally:
print("关闭数据连接")
print("程序即将结束")
- 产生异常,但没有捕获异常,仍会执行finally中的语句。(先执行finally中语句,再打印出异常信息)
try:
# 打印一个不存在的变量,将产生NameError异常
print(num)
# 读取一个不存在的文件,将产生FileNotFoundError异常
open("text.txt")
finally:
print("关闭数据连接")
print("程序即将结束")
- 没有异常,执行finally语句
try:
num = 20
print(num)
finally:
print("关闭数据连接")
print("程序即将结束")
7.5 异常传递
在开发过程中,经常会遇到函数嵌套调用,如果在函数内部调用的函数产生了异常,需要在外部函数中被捕获并处理,这就需要从内部调用的函数把产生的异常传递给外部函数,这个过程叫做异常传递。
def fun1():
# 打印一个不存在的变量,产生异常,但是不进行捕获
print(num)
def fun2():
try:
# 调用fun1()函数,捕获fun1()传递的异常
fun1()
except Exception as err:
print("程序执行产生异常 ", err)
7.6 raise抛出异常
如果想要在自己写的代码中遇到问题也抛出异常,可以使用Python提供的raise语句,并且也可以自定义异常类型。
def div(a,b)
if b == 0:
raise ZeroDivisionError
# raise ZeroDivisionError("异常原因:除法运算,除数不能为0!") # 把这个异常的解释作为参数传入到ZeroDivisionError异常中,当程序抛出异常时,连同异常的解释一起打印出来,便于理解抛出异常的原因
else:
return a/b
div(2,0)
7.7 自定义异常
除了使用Python内置的异常类之外,你还可以定义自己的异常类。自定义异常类应该继承自Exception类或其子类。这样做可以让你创建特定于你的应用程序的异常,并提供更多的错误信息。当这个自定义异常被抛出时,它可以像任何其他异常一样在except块中被捕获。
class MyCustomError(Exception):
def __init__(self, message):
self.message = message
def __str__(self):
return self.message
# 使用自定义异常
raise MyCustomError("发生了一个自定义错误")
7.8 异常的参数
在Python中,异常可以带参数,这些参数可以在except块中被访问。这些参数通常包含错误消息和其他有关异常的信息。例如:
try:
# 可能会抛出异常的代码
pass
except ValueError as e:
print("捕获到 ValueError,错误信息:", e.args)
在这个例子中,e.args将包含传递给ValueError的参数。
7.9 异常的最佳实践
在抛出和捕获异常时,最好使用最具体的异常类,这样可以更精确地处理错误情况。应该避免使用过于通用的异常类,如Exception,因为这可能会隐藏其他更具体的错误。此外,当你需要重新抛出异常时,应该使用裸的raise语句,这样可以保留完整的堆栈跟踪。
7.10 异常处理的完整语法
try:
# 尝试执行的代码
pass
except ValueError:
# 处理ValueError
pass
except (TypeError, IndexError):
# 处理多个异常
pass
except Exception as e:
# 处理其他所有异常
print("发生异常:", e)
else:
# 如果没有异常发生,执行这里的代码
pass
finally:
# 无论是否发生异常,都会执行这里的代码
pass
在这个例子中,try块中的代码首先被执行。如果发生异常,它将被相应的except块捕获。如果没有异常发生,else块将被执行。无论是否发生异常,finally块总是会被执行。
通过使用这些异常处理机制,Python程序员可以编写更健壮、更易于维护的代码,并能够优雅地处理程序运行中可能出现的错误情况。
7.11 python标准异常
| 异常名称 | 描述 |
|---|---|
| BaseException | 所有异常的基类 |
| SystemExit | 解释器请求退出 |
| KeyboardInterrupt | 用户中断执行(通常是输入^C) |
| Exception | 常规错误的基类 |
| StopIteration | 迭代器没有更多的值 |
| GeneratorExit | 生成器(generator)发生异常来通知退出 |
| StandardError | 所有的内建标准异常的基类 |
| ArithmeticError | 所有数值计算错误的基类 |
| FloatingPointError | 浮点计算错误 |
| OverflowError | 数值运算超出最大限制 |
| ZeroDivisionError | 除(或取模)零 (所有数据类型) |
| AssertionError | 断言语句失败 |
| AttributeError | 对象没有这个属性 |
| EOFError | 没有内建输入,到达EOF 标记 |
| EnvironmentError | 操作系统错误的基类 |
| IOError | 输入/输出操作失败 |
| OSError | 操作系统错误 |
| WindowsError | 系统调用失败 |
| ImportError | 导入模块/对象失败 |
| LookupError | 无效数据查询的基类 |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| MemoryError | 内存溢出错误(对于Python 解释器不是致命的) |
| NameError | 未声明/初始化对象 (没有属性) |
| UnboundLocalError | 访问未初始化的本地变量 |
| ReferenceError | 弱引用(Weak reference)试图访问已经垃圾回收了的对象 |
| RuntimeError | 一般的运行时错误 |
| NotImplementedError | 尚未实现的方法 |
| SyntaxError | Python 语法错误 |
| IndentationError | 缩进错误 |
| TabError | Tab 和空格混用 |
| SystemError | 一般的解释器系统错误 |
| TypeError | 对类型无效的操作 |
| ValueError | 传入无效的参数 |
| UnicodeError | Unicode 相关的错误 |
| UnicodeDecodeError | Unicode 解码时的错误 |
| UnicodeEncodeError | Unicode 编码时错误 |
| UnicodeTranslateError | Unicode 转换时错误 |
| Warning | 警告的基类 |
| DeprecationWarning | 关于被弃用的特征的警告 |
| FutureWarning | 关于构造将来语义会有改变的警告 |
| OverflowWarning | 旧的关于自动提升为长整型(long)的警告 |
| PendingDeprecationWarning | 关于特性将会被废弃的警告 |
| RuntimeWarning | 可疑的运行时行为(runtime behavior)的警告 |
| SyntaxWarning | 可疑的语法的警告 |
| UserWarning | 用户代码生成的警告 |
八、日期和时间
8.1 time模块
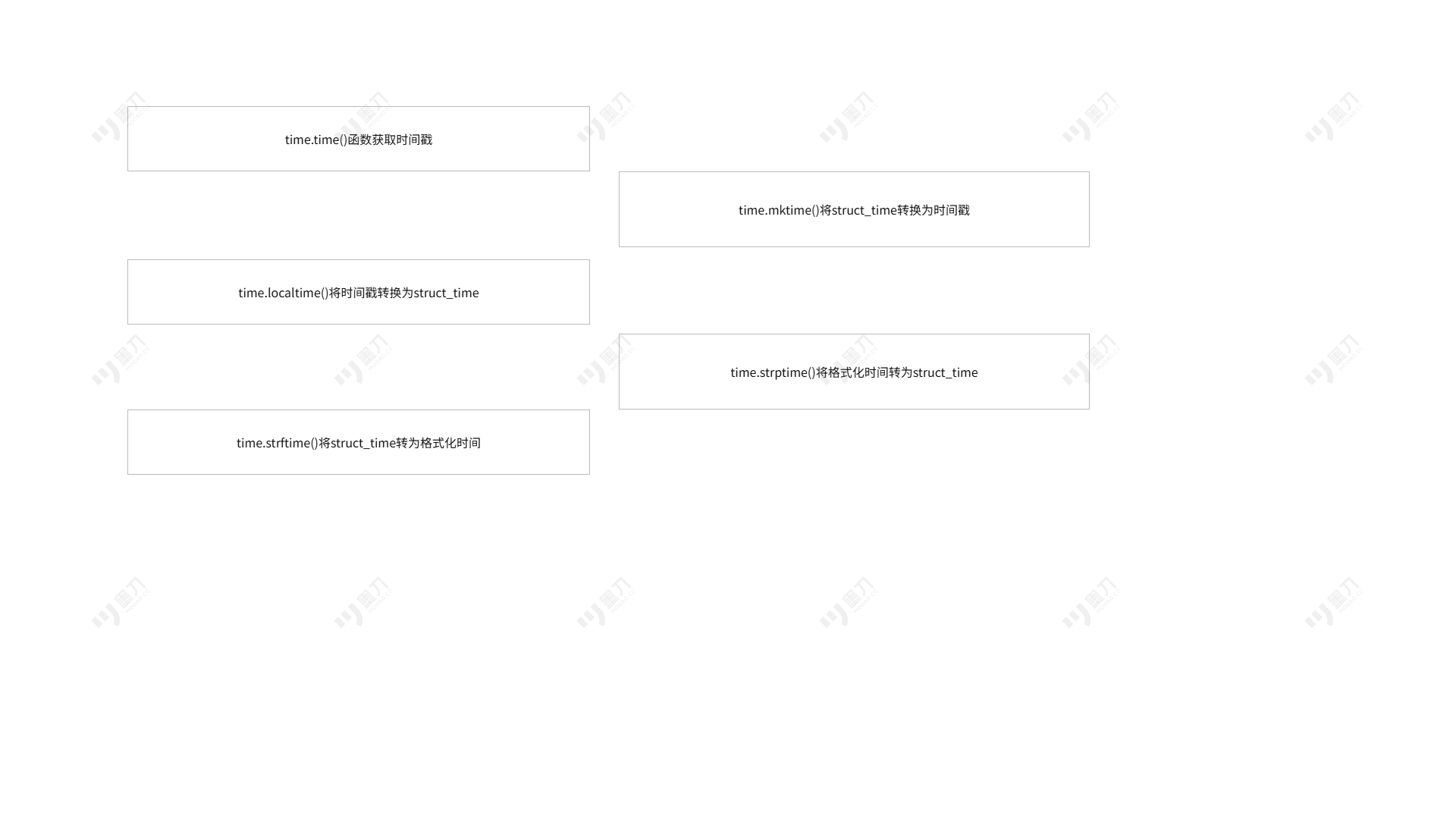
8.1.1 time 函数
调用time函数时,会返回当前的时间戳,返回的时间戳是以秒为单位的浮点数
import time
# 获取当前时间戳
print(time.time())
8.1.2 localtime([seconds])函数
localtime([seconds])函数可以传入一个可选参数,可选参数是以秒为单位的时间戳。如果不传入任何参数,则将当前时间戳转换成本地时间,返回一个time模块内置的struct_time元组。如果传入时间戳作为参数,则将时间戳格式化为本地时间,返回一个struct_time元组。
struct_time元组
| 序号 | 属性 | 值 | 含义 |
|---|---|---|---|
| 0 | tm_year | 2008 | 年份 |
| 1 | tm_mon | 1 到 12 | 月份 |
| 2 | tm_mday | 1 到 31 | 日期 |
| 3 | tm_hour | 0 到 23 | 小时 |
| 4 | tm_min | 0 到 59 | 分钟 |
| 5 | tm_sec | 0 到 61 (60或61 是闰秒) | 秒 |
| 6 | tm_wday | 0到6 (0是周一) | 一周的第几天 |
| 7 | tm_yday | 1 到 366(儒略历) | 一年的第几天 |
| 8 | tm_isdst | -1, 0, 1, -1是决定是否为夏令时的旗帜 | 是否夏令时 |
date_time = time.localtime()
print(date_time)
# 运行结果
time.struct_time(tm_year=2025, tm_mon=5, tm_mday=5, tm_hour=15, tm_min=55, tm_sec=5, tm_wday=0, tm_yday=125, tm_isdst=0)
8.1.3 strftime(format[,struct_time])函数
strftime(format[,struct_time])函数可以按照自定义的格式化参数将时间格式化,format是函数调用时传入的字符串类型的自定义格式化参数,他是由时间格式化符号表示的。第2个参数struct_time元组是可选参数,不传入该参数表示将当前时间格式化
时间格式化符:
| 格式化符号 | 说明 |
|---|---|
| %y | 两位数的年份表示(00-99) |
| %Y | 四位数的年份表示(000-9999) |
| %m | 月份(01-12) |
| %d | 月内中的一天(0-31) |
| %H | 24小时制小时数(0-23) |
| %I | 12小时制小时数(01-12) |
| %M | 分钟数(00-59) |
| %S | 秒(00-59) |
| %a | 本地简化星期名称,如:Wed |
| %A | 本地完整星期名称,如:Wednesday |
| %b | 本地简化的月份名称,如:Sep |
| %B | 本地完整的月份名称,如:September |
| %c | 本地相应的日期表示和时间表示,如:Wed May 5 16:08:58 2025 |
| %j | 年内的一天(001-366),每年的一月一日是一年的第一天 |
| %p | 本地A.M.或P.M.的等价符 |
| %U | 一年中的星期数(00-53)星期天为星期的开始 |
| %w | 星期(0-6),星期天为星期的开始 |
| %W | 一年中的星期数(00-53)星期一为星期的开始 |
| %x | 本地相应的日期表示,如05/05/2025 |
| %X | 本地相应的时间表示,如16:12:25 |
| %Z | 当前时区的名称 |
| %% | %号本身 |
# 默认格式化当前时间
print(time.strftime("当前时间: %Y-%m-%d %H:%M:%S"))
# 传入指定struct_time参数,对其格式化
print(time.strftime("指定时间: %Y-%m-%d %H:%M:%S", time.localtime(1514829722)))
8.1.4 strptime(date_time,format)函数
strptime函数可以将一个格式化的时间字符串转换为struct_time元组,第一个参数date_time表示格式化时间字符串,第二个参数format表示时间格式化方式
time_tuple= time.strptime("2025-05-05 16:19:35", "%Y-%m-%d %H:%M:%S")
print(time_tuple)
8.1.5 mktime(time_tuple)函数
mktime函数可以将一个时间元组转换成一个浮点型时间戳
current_time = time.mktime(time.localtime())
print(ts)
8.1.6 sleep(seconds)函数
sleep函数可以在程序运行过程中,让程序暂停运行,睡眠等待几秒钟
# 计时器
reverse_time = input("输入要倒计时的时间")
print("开始倒计时")
time.sleep(int(reverse_time))
print("时间到")
8.2 datetime模块
8.2.1 now()方法
datetime.datetime.now()方法用于获取程序运行的当前日期和时间,在这条调用now()方法的语句中,第1个datetime指的是模块1名称,第2个datetime指的是在datetime模块内定义的datetime类,在这个datetime类中定义了日期和时间相关的处理方法。now()方法默认返回值的格式是“YYYY-MM-DD HH:MM:SS.mmmmmm”。如果想对时间进行自定义格式化,可以调用strftime方法实现。
此外,可以通过now()方法返回值非常方便获取指定日期时间,如使用now().year获取年份等
# 获取当前日期时间
current_time = datetime.datetime.now()
print("默认格式: {}".format(current_time))
# 通过now()方法返回值获取当前日期时间
print("year: ", current_time.year)
print("month: ", current_time.month)
print("day: ", current_time.day)
print("hour: ", current_time.hour)
print("minute: ", current_time.minute)
print("second: ", current_time.second)
通过datetime类内置的获取指定日期时间的方法可以轻松实现两个不同日期时间的算术运算
start_time = datetime.datetime.now()
print("开始时间: ",start_time)
time.sleep(2)
end_time = datetime.datetime.now()
print("结束时间: ", end_time)
print("时间差: {} 秒".format(start_time.second - end_time.second)
8.2.2 strftime(format)方法
strftime(format)方法能够按照自定义的格式化方式对日期和时间进行格式化。函数需要传入一个字符串类型的format参数,该参数是由时间格式化符号组成的。
# 自定义日期时间格式化
format_time = datetime.datetime.now().strftime("%Y/%m/%d %H:%M:%S")
print("自定义格式: {}".format(format_time))
8.2.3 fromtimestamp(timestamp)方法
fromtimestamp(timestamp)方法可以对传入的时间戳timestamp参数以日期时间的形式进行格式化。该方法返回值的默认格式是“YYYY-MM-DD HH:MM:SS.mmmmmm”,还可以调用strftime(timestamp)方法将返回值以自定义的日期时间形式进行格式化。
# 将时间戳格式化为日期时间
ts = time.time() # 获取当前时间戳
print(datetime.datetime.formtimestamp(ts)) # 默认格式化
# 自定义格式化
print(datetime.datetime.fromtimestamp(ts).strftime("%Y/%m/%d %H:%M:%S"))
8.2.4 timedelta类
timedelta类是datetime模块内置的时间间隔类,在根据timedelta类创建时间间隔类对象时,可以传入days、hours、minutes、seconds、milliseconds、microseconds、weeks等参数的值来创建指定的时间间隔对象。如datetime.timedelta(days=1)表示创建一个一天时间间隔的对象。
# 计算昨天的日期时间,方法:昨天的日期 = 今天的日期 - 1天的时间间隔
today = datetime.datetime.today()
print("今天的日期:{}".format(today.strftime("%Y-%m-%d")))
days = datetime.timedelta(days=1) #1天的时间间隔
yesterday = today - days # 今天减去时间间隔得到昨天的日期时间
print("昨天的日期: {}".format(yesterday.strftime("%Y-%m-%d")))
九、文件操作
9.1 读写文件
9.1.1 打开文件
在Python中操作一个文件,首先要使用内置的open函数打开该文件,返回一个文件对象,才能够对该文件进行操作。使用open函数打开文件可以使用三种常用模式,分别是只读模式(默认,使用字母r表示)、只写模式(使用字母w表示)、追加模式(使用字母a表示)。只读模式只用于读取文件内容,不能向文件中写入数据;只写模式用于将数据覆盖写入到文件中;追加模式用于将数据追加写入到文件的末尾。
file = open("file.txt", "r") # 只读模式打开文件
file = open("file.txt", "w") # 只写模式打开文件
当打开一个不存在的文件时,只读模式会产生FileNotFound异常,而只写和追加这两种模式都会创建一个新的空文件。当然,如果文件存在,这三种模式都会正常打开一个文件,open函数会返回一个文件对象,通过操作这个文件对象,读取文件内容或者向文件写入数据。
注意:在操作文件时,如果读取的文件内容包含中文或者写入到文件的数据包含中文,为了避免出现中文乱码,可以在open函数中设置打开文件的编码格式为encoding="utf-8"。
9.1.2 写文件
- write()方法
Python内置的write()方法可以将字符串数据写入到文件中。注意,使用write()方法写入到文件中的内容不会自动换行。
如果使用只写模式“w”打开文件,那么write()方法会采用覆盖写的方式将字符串数据写入文件。也就是说如果写入的不是一个空文件,那么会将原文件内容清空,然后写入新的内容。
file = open("test.txt", "w")
file.write("hello Python!") # 无换行
file.write("Python3.12")
如果需要在原文件末尾追加数据而不是覆盖原有内容,那么使用追加模式"a"打开文件
file = open("test.txt", "a")
file.write("hello Python! \n")
file.write("Python3.12 \n")
使用write()方法如果想实现换行,可以在写入的数据中需要换行的地方加入换行符'\n'
- writelines()方法
writelines()方法可以将一个序列中的多个字符串一次性写入到文件中
f = open("test.txt", "w", encoding="utf-8")
f.writelines(["张三\n","李四\n","王五\n"]) # '\n'实现换行
- close()方法
使用文件对象操作完文件需要使用close()方法关闭文件,如果不显示调用close()方法关闭文件,在程序执行完也会自动关闭文件,操作系统会把待写入文件的数据缓存起来,如果此时由于某些原因操作系统崩溃,就会造成缓存的数据丢失,无法将缓存的数据写入到文件。所有在写代码时,当使用完一些资源,要对其释放或关闭,避免资源浪费,减少程序出错的风险。
f = open("test.txt", "w", encoding="utf-8")
f.writelines(["张三\n","李四\n","王五\n"]) # '\n'实现换行
f.close() # 关闭文件
Python还提供了一种安全打开文件的方式,使用“with”关键字配合open函数打开文件,通过这种方式,当操作完文件后程序会自动调用close()方法,不需要显示地调用close()方法,这种用法既简洁又安全。有关文件的操作,推荐使用with打开。
# 使用with关键字安全打开关闭文件
with open("test.txt", "w", encoding="utf-8") as f:
f.writelines(["张三\n","李四\n","王五\n"])
9.1.3 读文件
- read()方法
read()方法可以一次性从文件中读取所有文件内容
with open("test.txt", "r", encoding="utf-8") as f:
data = f.read()
print(data)
- readlines()方法
readlines()方法可以按照行的方式把整个文件中的内容一次全部读取出来,返回结果是一个列表,文件中的一行数据就是列表中的一个元素,由于文件中每行末尾包含一个不可见的换行符'\n',所以列表中每个元素的最后也包含一个换行符'\n'
with open("test.txt", "r", encoding="utf-8") as f:
lines = f.readlines()
print(lines)
# 循环遍历lines,打印每行内容
for i in range(0, len(lines)):
print("第{}行,内容:{}".format(i,lines[i])) # 输出结果两行之间出现空行,原因是print函数默认换行输出,但每行数据后还有一个换行符
# print去除换行输出
for i in range(0, len(lines)):
print("第{}行,内容:{}".format(i,lines[i]),end="")
9.2 文件管理
9.2.1 rename(oldfile,newfile)函数
rename函数用于对文件或文件夹重命名。注意:如果待操作的文件或文件夹不存在,执行rename函数则程序会报错。
注意:在执行重命名文件的操作时,如果没有指定文件的绝对路径,那么会在程序执行的当前路径下(相对路径)下查找文件
import os
os.rename("test.txt", "测试.txt")
9.2.2 remove(path)函数
remove函数用于删除指定文件
注意:在执行删除文件时,如果没有指定文件的绝对路径,那么会在程序执行的当前路径下(相对路径)下查找文件
import os
os.remove("测试.txt")
9.2.3 mkdir(path)函数
mkdir函数用于在指定的路径下创建新文件夹
import os
os.mkdir("d://testdir")
9.2.4 getcwd()函数
getcwd函数用于获取程序运行的绝对路径
import os
print(os.getcwd())
9.2.5 listdir(path)函数
listdir函数用于获取指定路径下的文件列表(包括文件和文件夹),函数返回值是一个列表
import os
lsdir = os.listdir("./")
print(lsdir)
9.2.6 rmdir(path)函数
rmdir函数用于删除指定路径下的空文件夹
注意:如果使用rmdir函数用于删除一个非空文件夹,程序将报错
import os
os.remir("./datas")
如果想要删除一个非空文件夹,可以引入shutil模块的rmtree(path)函数,不建议在程序中直接删除一个非空文件夹,有可能会误删,最好确认无误后再删除。
9.3 JSON文件操作
注意:
python中的元组和列表再JSON中都是以列表形式存在,Python中的布尔类型True和False在JSON中会被转成小写true和false,Python中的空类型None在JSON中会被转换为null。
在Python中操作JSON格式数据要引入Python的json模块,json模块提供了丰富的操作JSON格式数据的函数,常用的几个函数如下:
- dumps(python_dict):将Python字典数据转换为JSON编码的字符串;
- loads(json_str):将JSON编码的字符串转换为Python的字典;
- dump(python_dict,file_object):将python字典数据转换为JSON编码的字符串,并写入JSON文件;
- load(json_file_object):从JSON文件中读取数据,并将JSON编码的字符串转换为Python的字典
9.3.1 dumps(python_dict)函数
import json
user_info_dict = {
"name":"张三",
"age":20,
"high":192.2,
"language":["Python", "Java", "C++"],
"study":{"AI":"Python", "Web":"Java", "BigData":"hadoop"},
"is_VIP":True,
"phone":None
}
json_str = json.dumps(user_info_dict)
print(json_str)
9.3.2 loads(json_str)函数
import json
python_dict = json.loads(json_str)
# 转换后的数据类型
print("转换后的数据类型为: {}".format(type(python_dict)))
print(python_dict)
9.3.3 dump(python_dict, file_object)函数
import json
user_info_dict = {
"name":"张三",
"age":20,
"high":192.2,
"language":["Python", "Java", "C++"],
"study":{"AI":"Python", "Web":"Java", "BigData":"hadoop"},
"is_VIP":True,
"phone":None
}
with open("./user_info.json", "w", encoding="utf-8") as f:
json.dump(user_info_dict, f) # 传入的是文件操作对象,不是文件路径
9.3.4 load(json_file_object)函数
import json
with open("./user_info.json", "r", encoding="utf-8") as f:
user_info_dict = json.load(f)
print("类型为:{}".format(type(user_info_dict)))
print(user_info_dict)
9.4 CSV文件操作
CSV文件内容默认使用逗号分隔,可以使用Excel打开,由于CSV文件是一种文本文件,所以还可以使用其他文本编辑器打开。CSV文件内的数据没有数据类型,所有数据都是字符串。
9.4.1 写入CSV文件
操作CSV文件需要引入csv模块,在csv模块中提供了两个方法可以向csv文件写入数据分别为:
- writerow([row_data]):一次写入一行数据
- writerows([[row_data],[row_data],...]):一次写入多行数据
import csv
# 用户信息列表,嵌套列表内的每一个小列表是一行数据
datas = [["name","age"],["张三", 20],["李四",22]] # 嵌套列表内的第一个列表是标题
with open("./user_info.csv", "w", encoding="utf-8") as f:
# writer函数会返回一个writer对象,通过writer对象向csv文件写入数据
writer = csv.writer(f)
# 循环遍历列表,一次写入一行数据
for row in datas:
writer.writerow(row)
# 把数据一次性写入csv文件
writer.writerows(datas)
9.4.2 读取csv文件
在csv模块中提供了读取csv文件的reader方法,reader方法会根据打开的文件对象返回一个可迭代对象,然后遍历这个对象读取csv文件中每一行数据。
第一行数据是标题,之后的数据是信息
import csv
with open("./user_info.csv", "r", encoding="utf-8") as f:
reader = csv.reader(f) # 返回一个reader可迭代对象
for row in reader:
print(row) # row是一个列表
print(row[0]) # 通过索引获取列表中的元素
print(row[1])
print("-------------------------")
十、正则表达式
10.1 re模块
在Python中内置了处理正则表达式的模块re模块,有了re模块使我们在程序中能够非常方便地使用正则表达式对字符串进行各种规则匹配检查。在re模块中封装了很多正则表达式相关的函数,其中比较常用的一个函数是match函数,用于对字符串进行正则匹配。
match(pattern,string)函数描述如下:
- 参数说明:pattern表示正则表达式;string表示待匹配字符串
- 功能:对待匹配字符串按照从左向右的顺序,使用正则表达式进行匹配。如果待匹配字符串从左侧开始有一个字串能够与正则表达式匹配成功,那么将不再向后继续匹配,此时match函数返回一个匹配成功的Match对象,否则返回None。
import re
str = "python java python c++"
rs = re.match("python", str)
print(rs) # 返回匹配成功的子串在原字符串中的索引范围,匹配到第一个子串就停止,不会继续匹配
如果想要直接获取匹配的子串,可以调用Match对象的group方法实现
import re
str = "python java python c++"
rs = re.match("python", str)
print(rs.group()) # 返回匹配成功的子串
10.2 单字符匹配
常用单字符匹配符号:
| 符号 | 描述 |
|---|---|
| . | 匹配除'\n'之外的任意单个字符 |
| \d | 匹配0-9之间的一个数字,等价于[0~9] |
| \D | 匹配一个非数字字符,等价于[^0~9] |
| \s | 匹配任意空白字符,如空格、制表符'\t'、换行符'\n'等 |
| \S | 匹配任意非空白字符 |
| \w | 匹配单词字符,包括字母、数字、下划线 |
| \W | 匹配非单词字符 |
| [] | 匹配[]中列举的字符 |
import re
# 用'.'匹配除换行符'\n'外的任意单个字符
rs = re.match(".", "1") # 匹配一个包含数字的字符串
print(rs.group()) # 若没有匹配上rs.group()会报错
rs = re.match(".", "a") # 匹配一个包含单字符的字符串
print(rs.group())
rs = re.match(".", "abc") # 匹配一个包含多个字符的字符串,虽然在这个字符串中有多个字符,但是通过点号值匹配到其中第一个”a“。如果想要匹配多个字符,在正则表达式中就要多写几个点号
print(rs.group())
rs = re.match("...", "abc")
print(rs.group())
rs = re.match(".", "\n")
print(rs.group())
# 使用'\s'匹配任意空白字符
rs = re.match("\s", "\t") # 匹配制表符
print(rs.group())
rs = re.match("\s", "\n") # 匹配换行符
print(rs.group())
rs = re.match("\s", " ") # 匹配空格
print(rs.group())
# 匹配"[]"中列举的字符,"[]"中列举的字符之间是或的关系
# 匹配以h或H开头的字符串
rs = re.match("[Hh]", "hello")
print(rs.group())
rs = re.match("[Hh]", "Hello")
print(rs.group())
# 匹配0到9任意数字,方法一
rs = re.match("[0123456789]", "3")
print(rs.group())
# 匹配0到9任意数字,方法二
rs = re.match("[0-9]", "3")
print(rs.group())
10.3 数量表示
数量表示符号:
| 符号 | 描述 |
|---|---|
| * | 匹配一个字符出现0次或多次 |
| + | 匹配一个字符至少出现一次,等价表示{1,} |
| ? | 匹配一个字符至多出现一次,也就是出现0次或1次,等价表示{0,1} |
| {m} | 匹配一个字符出现m次 |
| {m,} | 匹配一个字符至少出现m次 |
| {m,n} | 匹配一个字符出现m到n次 |
示例:检查用户信息是否完整
# 存储用户信息列表,每条用户信息包含三个字段:姓名、手机号、年龄
user_infos = ["汤姆,18890921293,10", "Linken,185555555555,20", "David,18293841834,03", "Lilly,19665233968,52","LiMing,19665233968abc,52"]
for user in user_infos:
# 使用正则表达式检查用户信息是否完整
rs = re.match("[\w\W]+,1[35789]\d{9},[1-9]+[0-9]+", user)
if rs != None:
print("用户信息: {}".format(rs.group()))
else:
print("用户信息不完整: {}".format(user))
# 运行结果
用户信息: 汤姆,18890921293,10 # “汤姆”非单词字符 \W
用户信息不完整: Linken,185555555555,20 # 手机号长度不符合
用户信息不完整: David,18293841834,03# 年龄不符合
用户信息: Lilly,19665233968,52
用户信息不完整: LiMing,19665233968abc,52
10.4 边界表示
边界表示符号:
| 符号 | 描述 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
# 验证标识符名是否合法
def reg_identifier(str):
# 正则表达式匹配以数字开头的字符串
rs = re.match("^[0-9]\w*",str)
if rs is not None:
# 如果str以数字开头,则表示是非法标识符
return False
else:
return True
print("标识符1_name是否合法: {}".format(reg_identifier("1_name")))
print("标识符name_1是否合法: {}".format(reg_identifier("name_")))
10.5 转义字符
10.5.1 转义字符'\'
# 用正则表达式判断邮箱
# 合法的163邮箱以4到10个单词字符开始,以@163.com结束
# 合法邮箱
rs = re.match("\w{4,10}@163.com$", "python2025@163.com")
print(rs)
# 非法邮箱
rs = re.match("\w{4,10}@163.com$", "abc@163.com")
print(rs)
# 非法邮箱
rs = re.match("\w{4,10}@163.com$", "vip_python2025@163.com")
print(rs)
# 非法邮箱 ——由于'.'号被解析为'h'导致通过验证, "."号具有特殊含义,它是一个单字符匹配符合,表示匹配除换行符'\n'外的任意字符
rs = re.match("\w{4,10}@163.com$", "python2025@163hcom")
print(rs)
# 解决由于特殊字符造成的歧义方法:使用转义字符'\'将正则表达式中的'.'转换为普通字符
rs = re.match("\w{4,10}@163\.com$", "python2025@163hcom")
print(rs)
rs = re.match("\w{4,10}@163\.com$", "python2025@163.com")
print(rs)
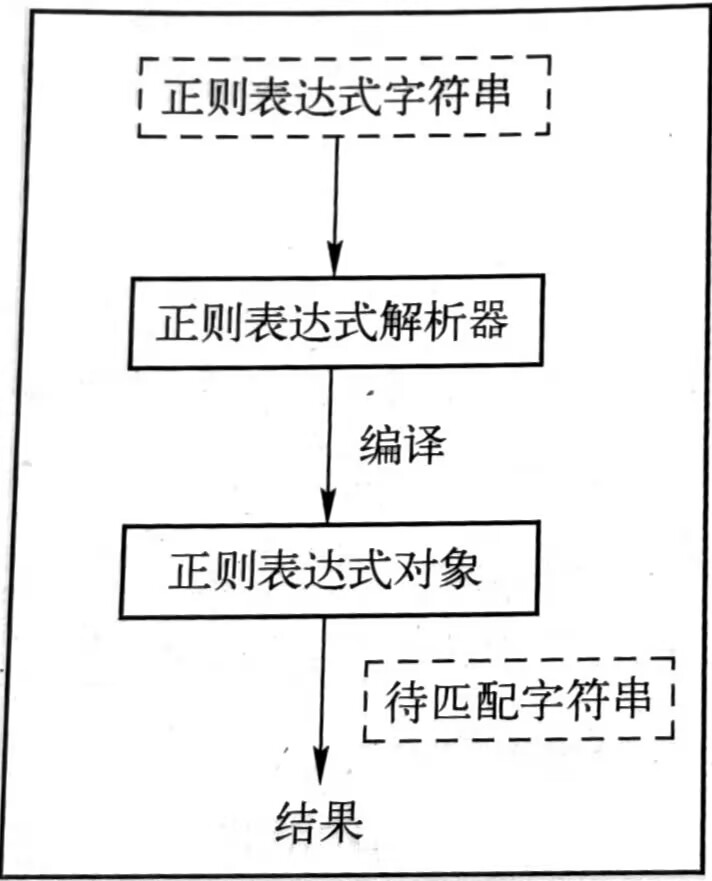
Python中的正则表达式执行流程如下图所示,在代码执行时,首先将正则表达式字符串传递给Python内置的正则表达式解析器,经过编译生成一个正则表达式对象,然后通过正则表达式对象取匹配待匹配字符串,最终返回匹配结果。
10.5.2 Python原生字符串
str = "abc\\def"
print(str)
# 运行结果
abc\def
运行结果中只打印字符串中的一个'\',因为'\'具有转义功能,两个斜杠中的第一个斜杠把第二个斜杠转义成为普通字符。如果需要打印多个斜杠,则比较麻烦,而Python中的原生字符串可以很好解决这个问题。原生字符串的表示方法就是在字符串前添加一个字母'r'。原生字符串可以取消字符串中斜杠的特殊功能,使它只表示普通的字符。
str = r"abc\\def"
print(str)
# 运行结果
abc\\def
10.5.3 正则表达式中使用原生字符串
str = "\python"
# 使用四个斜杠匹配一个斜杠,使用非原生字符串定义正则表达式匹配规则
rs = re.match("\\\\\w+", str)
print(rs)
# 使用原生字符串定义正则表达式匹配规则
rs = re.match(r"\\\w+", str)
print(rs)
# 运行结果
<re.Match object; span=(0, 7), match='\\python'> # match中两个斜杠原因:前一个斜杠对后一个斜杠进行转义,使其成为普通字符
<re.Match object; span=(0, 7), match='\\python'>
- 分析使用非原生字符串定义的正则表达式的执行流程:因为字符串中斜杠具有转换功能,索引正则表达式字符串""\\\\\w+"中的前四个斜杠会被转换成两个斜杠,变成"\\\w+"传递给正则表达式解析器。在正则表达式中斜杠也具有转换功能,所以解析器会将"\\\w+"中的前两个斜杠转换成一个斜杠,变成"\\w+"去匹配字符串"\python"。
- 分析使用原生字符串定义的正则表达式的执行流程:因为使用了原生字符串定义的正则表达式已经取消了斜杠的转换功能,所以会以"\\\w+"的形式传递给正则表达式解析器,解析器将"\\\w+"中的前两个斜杠转换成一个斜杠,变成"\\w+"去匹配"\python"
使用原生字符串定义的正则表达式更加简介,代码可读性更强,推荐使用原生字符串编写正则表达式
10.6 匹配分组
匹配邮箱时如果想要匹配多种类型的邮箱,可以使用分组来实现。
分组符号:
| 符号 | 描述 |
|---|---|
| | | 连接多个表达式,表达式之间是“或”的关系,匹配“|”连接的任何一个表达式 |
| () | 将括号中字符作为一个分组 |
| \NUM | 结合"()"分组使用,引用分组NUM(NUM表示分组的编号)对应的匹配规则 |
| (?P<name>) | 给分组起别名 |
| (?P=name) | 根据组名使用分组中的正则表达式 |
示例:使用分组分配多种类型邮箱
# 匹配163、QQ、Outlook邮箱
rs1 = re.match(r"\w{4,10}@(163|qq|outlook)\.com$", "python2025@163.com")
print(rs1)
rs2 = re.match(r"\w{4,10}@(163|qq|outlook)\.com$", "python@qq.com")
print(rs2)
示例:使用正则表达式分组匹配网页标签
# 正确的网页标签
html_data = "<head><title>python</title></head>"
rs = re.match(r"<.+><.+>.+</.+></.+>", html_data)
print(rs)
# 错误的网页标签
html_data = "<head><title>python</head></title>" # 标签结尾混乱
rs = re.match(r"<.+><.+>.+</.+></.+>", html_data)
print(rs)
# 运行结果
<re.Match object; span=(0, 34), match='<head><title>python</title></head>'>
<re.Match object; span=(0, 34), match='<head><title>python</head></title>'>
从结果来看,无论网页标签是否正确,都被匹配到,第二种并不是我们想要的,不能识别错误的网页标签,使用分组来解决这个问题。
# 正确的网页标签
html_data = "<head><title>python</title></head>"
rs = re.match(r"<(.+)><(.+)>.+</\2></\1>", html_data)
print(rs)
# 错误的网页标签
html_data = "<head><title>python</head></title>" # 标签结尾混乱
rs = re.match(r"<(.+)><(.+)>.+</\2></1>", html_data)
print(rs)
# 运行结果
<re.Match object; span=(0, 34), match='<head><title>python</title></head>'>
None
当正则表达式中分组比较多,再使用"\NUM"引用分组就会比较麻烦,需要记住每一个分组的编号,容易产生引用错误。可以通过给分组起别名来解决,通过别名引用已经定义过的分组。
# 正确的网页标签
html_data = "<head><title>python</title></head>"
rs = re.match(r"<(?P<g1>.+)><(?P<g2>.+)>.+</(?P=g2)></(?P=g1)>", html_data)
print(rs)
# 错误的网页标签
html_data = "<head><title>python</head></title>" # 标签结尾混乱
rs = re.match(r"<(?P<g1>.+)><(?P<g2>.+)>.+</(?P=g2)></(?P=g1)>", html_data)
print(rs)
# 运行结果
<re.Match object; span=(0, 34), match='<head><title>python</title></head>'>
None
建议当正则表达式分组比较少时,可以使用编号引用分组,当分组比较多时,可以考虑使用别名引用分组。
10.7 内置函数
10.7.1 compile函数
使用re模块内置的compile(pattern)函数编译正则表达式,返回一个正则表达式对象,在匹配时可以多次复用一个正则表达式对象进行匹配。性能方面:预编译模式(compile)在多次匹配时更高效,但单次调用(直接match())时差异不大
pattern = re.compile(r"\w{4,10}@163\.com$")
rs = pattern.match("1234@163.com") # 调用编译对象的match方法
print(rs)
rs = pattern.match("234@163.com")
print(rs)
rs = pattern.match("1234@163hcom")
print(rs)
# 运行结果
<re.Match object; span=(0, 12), match='1234@163.com'>
None
None
10.7.2 search函数
search(pattern,str)函数的功能是从左到右在字符串的任意位置搜索第一个被正则表达式匹配的子字符串
rs = re.search("python", "hi python, i like python")
print(rs)
# 运行结果
<re.Match object; span=(3, 9), match='python'>
10.7.3 findall函数
findall(pattern,str)函数的功能是在字符串中查找正则表达式匹配成功的所有子字符串,返回匹配成功的结果列表
infos = "Tom,13800002202; David,15029181029"
list = re.findall("1[35789]\d{9}", infos)
print(list)
# 运行结果
['13800002202', '15029181029']
infos = "Tom, python@163.com; David,python@qq.com; Lili, abc@qq.com"
list = re.findall(r"(\w{3,20}@(163|qq)\.com)", infos) # 结果返回()内的内容
print(list)
# 运行结果
[('python@163.com', '163'), ('python@qq.com', 'qq'), ('abc@qq.com', 'qq')]
10.7.4 finditer函数
finditer(pattern,str)函数的功能是在字符串中查找正则表达式匹配成功的所有子字符串,返回结果是一个可迭代对象Iterator,Iterator中的每个元素都是正则表达式匹配的一个子字符串。
infos = "Tom,13800002202; David,15029181029"
lter_obj = re.finditer("1[35789]\d{9}", infos)
for iter in lter_obj:
print(iter.group())
# 运行结果
13800002202
15029181029
10.7.5 sub函数
sub(pattern,repl,str) 函数的功能是将正则表达式pattern匹配到的子字符串使用新的字符串repl替换掉。返回结果是替换之后的新字符串,原字符串str值不变。
# 将空字符替换成逗号
stu = "Tom 138143221443 Male"
stu_new = re.sub("\s",",",stu) # \s匹配空字符
print("stu: {}".format(stu))
print("stu_new: {}".format(stu_new))
# 运行结果
stu: Tom 138143221443 Male
stu_new: Tom,138143221443,Male
10.8 贪婪与非贪婪模式
- 贪婪模式:Python中的正则表达式解析器默认采用贪婪模式去匹配字符,也就是尽可能多地匹配字符
- 非贪婪模式:与贪婪模式相反,是尽可能少地匹配字符
启用非贪婪模式的方法:在表示数量的符号,如“*”“?”“+”"{m,n}"等的后面添加一个问好“?”,这样正则表达式解析器就会采用非贪婪模式去匹配字符
# 贪婪模式
print("---------贪婪模式----------")
rs = re.findall("python\d*", "python12345") # 任意多个数字
print(rs)
rs = re.findall("python\d+", "python12345") # 至少出现一次数字
print(rs)
rs = re.findall("python\d{2,}", "python12345") # 至少出现两次数字
print(rs)
rs = re.findall("python\d{1,4}", "python12345") # 出现2次到4次数字
print(rs)
# 非贪婪模式
print("---------非贪婪模式----------")
rs = re.findall("python\d*?", "python12345") # "*"最少匹配0个
print(rs)
rs = re.findall("python\d+?", "python12345") # "+"最少匹配1个
print(rs)
rs = re.findall("python\d{2,}?", "python12345") # "{2,}"最少匹配2个
print(rs)
rs = re.findall("python\d{1,4}?", "python12345") # "{1,4}" 最少匹配1个
print(rs)
# 运行结果
---------贪婪模式----------
['python12345']
['python12345']
['python12345']
['python1234']
---------非贪婪模式----------
['python']
['python1']
['python12']
['python1']
贪婪模式下,每个正则表达式都会尽可能多地匹配字符,也就是能匹配就匹配。在非贪婪模式下,每个正则表达式都会尽可能少地匹配字符,也就是能不匹配就不匹配
十一、网络编程
11.1 网络编程基础
- HTTP (HyperText Transport Protocol)
- URL (Uniform Resource Locator)
- HTTP请求方式:
- GET
- POST
- 状态码
11.2 urllib库
urllib库是Python内置的HTTP请求库,urllib库内置模块有:
| 模块 | 描述 |
|---|---|
| urllib.request | HTTP请求模块,在程序中模拟浏览器发送的HTTP请求 |
| utllib.error | 异常处理模块,捕获由于HTTP请求问题产生的异常,并进行处理 |
| urllib.parse | URL解析模块,提供了处理URL的工具函数 |
| urllib.robotparser | robot.txt解析模块,网站通过robot.txt文件设置爬虫可抓取的网页 |
11.2.1 urllib.request.urlopen函数
urllib库中request模块内置的urlopen函数用于向目标URL地址发送请求,返回一个HTTPResponse类型对象,通过该对象获取响应内容。
函数常用参数如下:
- url:目标URL访问地址
- data:默认值是None,表示以GET方式发送请求,如果改为以POST方式发送请求,需要传入data参数值
- timeout:访问超时时间,有时由于网络问题或者目标站点服务器处理请求时间较长可能会产生超时异常,可以通过设置timeout参数延长超时时间
import urllib.request # 一定要引用到模块
# 发送GET请求
response = urllib.request.urlopen("http://www.baidu.com")
content = response.read().decode("utf8") # 获取网页内容,并使用utf8编码对内容进行转码
print(content)
import urllib.parse
# 发送POST请求
# 与HTTP请求一起发送的数据
param_dict = {"key":"hello httpbin!"}
# 调用urlencode函数将字典类型数据转成字符串
param_str = urllib.parse.urlencode(param_dict)
# 将传输的数据封装成为一个bytes对象
param_datas = bytes(param_str,encoding="utf8")
# 在urllib.request.urlopen中传入data参数值,表示将发送一个POST请求
response = urllib.request.urlopen("http://httpbin.org/post", param_datas)
content = response.read().decode("utf8")
print(content)
# 超时时间
response = urllib.request.urlopen("http://www.baidu.com", timeout=0.01)
print(response.read().decode("utf8"))
# 运行结果
raise URLError(err)
urllib.error.URLError: <urlopen error timed out>
# 获取相应状态码和头信息
response = urllib.request.urlopen("http://www.baidu.com")
print(response.read().decode("utf8"))
print("响应状态码:{}".format(response.status))
print("响应头信息: {}".format(response.getheaders())) # getheaders()可以获取全部响应头信息
print("响应头信息中的日期: {}".format(response.getheader("Date"))) # getheader()可以获取头信息中指定的一条信息
11.2.2 urllib.request.Request类
使用urlopen函数可以向目标url地址发送基本的请求信息,参数比较简单,但无法完成一些复杂的请求,比如在请求中加入headers头信息等。对于复杂的请求操作可以使用urllib库内置的Request类构建一个Request对象,给这个对象添加更丰富的属性值,完成复杂的请求操作。
Requst类的构造方法有六个参数,分别为:
| 参数名称 | 是否必选 | 描述 |
|---|---|---|
| url | 是 | HTTP请求的目标URL地址 |
| data | 是 | HTTP请求要传输的数据,数据是bytes字节流类型 |
| headers | 否 | 请求头信息,头信息使用字典存储 |
| origin_req_host | 否 | 发起HTTP请求的主机名称或IP地址 |
| unverifiable | 否 | 表示这个请求是否为无法验证的,默认值是False,用户没有足够权限来选择接收这个请求的结果。例如,请求一个HTML文档中的图片,但是我们没有自动抓取图像的权限,这时unverifiable值就是True |
| method | 否 | 发起HTTP请求的方式,如GET、POST等 |
import urllib.parse
url = "http://httpbin.org/post"
# 设置浏览器信息
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36"}
data_dict = {"word": "hello httpbin!"}
# 将字典类型数据转换为bytes字节流
data = bytes(urllib.parse.urlencode(data_dict),encoding="utf8")
# 创建Request对象
request_obj = urllib.request.Request(url=url, data = data, headers = headers, method = "POST")
# 除在构造Request对象时添加headers头信息,也可通过Request对象也可动态添加headers头信息
request_obj.add_header("Content-Type", "application/x-www-form")
request_obj.add_header("Link","1234")
# 发送请求获取响应
response = urllib.request.urlopen(request_obj)
print(response.read().decode("utf8"))
# 运行结果
{
"args": {},
"data": "word=hello+httpbin%21",
"files": {},
"form": {},
"headers": {
"Accept-Encoding": "identity",
"Content-Length": "21",
"Content-Type": "application/x-www-form",
"Host": "httpbin.org",
"Link": "123",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-681ad209-637323bb406989e31bedc7c3"
},
"json": null,
"origin": "61.190.198.10",
"url": "http://httpbin.org/post"
}
11.2.3 urllib.error异常处理模块
当发起一个HTTP请求时,可能会因为各种原因导致请求出现异常,比如请求的网页不存在或者请求的服务器无法响应等。为了提高程序的稳定性,需要捕获这些异常,还可以根据需要针对捕获到的异常做进一步的处理。
Python内置了异常处理模块urllib.error,在该模块中定义了两个常用的异常,分别是URLError和HTTPError,其中HTTPError是URLError的子类。
- URLError
通过reason属性可以获取产生URLError的原因。产生URLError的原因有两种:
- 网络异常,失去网络连接
- 访问的服务器不存在,服务器连接失败
# 访问一个不存在的url,捕获URLError异常
import urllib.request
import urllib.error
# 一个不存在的链接
url = "http://hahaha.com"
try:
request_obj = urllib.request.Request(url = url)
response = urllib.request.urlopen(request_obj)
except urllib.error.URLError as e:
print(e.reason)
# 运行结果
[WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
- HTTPError
使用urlopen函数发送一个HTTP请求,会返回一个Response响应对象,该对象包含一个响应状态码,如果urlopen函数不能处理,就会产生一个HTTPError异常,捕获到这个异常后,可以通过HTTPError内置的code属性获取响应状态码
# 访问一个不存在的url,捕获HTTPError和URLError,并获取异常原因、响应状态码、请求头信息
import urllib.request
import urllib.error
# 一个不存在的链接
url = "http://douban.com/haha" # 该链接不存在,但服务器存在,服务器返回响应
try:
response = urllib.request.urlopen(url)
except urllib.error.HTTPError as e:
print("捕获HTTPError异常,异常原因是:", e.reason)
print("响应状态码: ",e.code)
print("请求头信息: ",e.headers)
except urllib.error.URLError as err:
print(err.reason)
# 运行结果
捕获HTTPError异常,异常原因是:
响应状态码: 418
请求头信息: Date: Wed, 07 May 2025 03:46:08 GMT
Content-Length: 0
Connection: close
Server: dae
HTTPError是URLError的子类,如果两个异常全部捕获,需要先捕获HTTPError,再捕获URLError,否则将无法捕获到HTTPError。
11.3 requests库
requests库是基于urllib开发的HTTP相关操作库,相比直接使用urllib库更加简洁、易用。requests库是Python的第三方库,需要单独安装才能使用。
11.3.1 安装requests库
# 1. 使用pip或pip3命令安装requests库
pip install requests
pip3 install requests
# 2. 验证安装是否成功
#进入Python交互模式,使用import引入requests库,然后通过requests内置的get方法访问百度,如果返回的状态码是200,则表示成功向百度发送了一次GET请求,同时也验证了requests库安装成功
import requests
requests.get("http://www.baidu.com")
# 运行结果
C:\Users\xxx>python
Python 3.12.1 (tags/v3.12.1:2305ca5, Dec 7 2023, 22:03:25) [MSC v.1937 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import requests
>>> requests.get("http://www.baidu.com")
<Response [200]>
>>>
11.3.2 requests库基本使用方法
requests库为了更加清晰、方便地发送不同类型的请求,分别提供了发送GET请求的get函数。发送POST请求的post函数。使用这两个函数发送请求成功后,会返回一个request.models.Response对象,通过Response对象内置的方法可以获取更多我们想要的信息。
- GET请求
使用requests库内置的get函数可以发起一次GET请求,通常在get函数中传入两个参数,第一个必选参数是要访问的URL,第二个可选参数是一个命名参数params,该参数的值会被传输到目标站点服务器。
import requests
response = requests.get("http://httpbin.org/get")
print("response类型: {}".format(type(response)))
print("状态码: ", response.status_code)
# 获取响应内容
content = response.text
print(content)
# 运行结果
response类型: <class 'requests.models.Response'>
状态码: 200
{
"args": {},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-681b1bce-44f5436547865da265d755ba"
},
"origin": "107.175.178.194",
"url": "http://httpbin.org/get"
}
Response对象还有更多的属性可以获取到不同的数据:
- content: 获取二进制数据,例如:服务端返回的图片、视频等都是由二进制码组成的
- url: 获取请求的url
- encoding: 获取响应内容的编码格式
- cookies: 获取cookies信息
- headers: 获取headers信息
发送GET请求时,如果想要传输一些数据,需要在URL后面添加一个问好“?”,在问号后面添加需要传输的数据,数据是以“key-value”键值对的形式组织的,多个数据之间用“&”分隔。
response = requests.get("http://httpbin.org/get?name='张三'&age=20")
print("请求的url: ",response.url)
print("响应的cookies: ", response.cookies)
print("响应的headers: ", response.headers)
print("响应的内容: ", response.text)
# 运行结果
请求的url: http://httpbin.org/get?name='%E5%BC%A0%E4%B8%89'&age=20
响应的cookies: <RequestsCookieJar[]>
响应的headers: {'Connection': 'close', 'Content-Length': '385', 'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Type': 'application/json', 'Date': 'Wed, 07 May 2025 08:46:15 GMT', 'Server': 'gunicorn/19.9.0'}
响应的内容: {
"args": {
"age": "20",
"name": "'\u5f20\u4e09'"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-681b1dd7-71205df22d389bb8161fcefe"
},
"origin": "107.175.178.194",
"url": "http://httpbin.org/get?name='\u5f20\u4e09'&age=20"
}
以上添加参数的方式比较繁琐,如果需要传输更多参数也会使得代码可读性变差,可以将待添加的参数以字典的形式存储,然后将参数字典赋值给get函数中的params参数。
data = {
"key":"python",
"pageSize": 10,
"currentPage": 2
}
response = requests.get("http://httpbin.org/get", params=data)
print("响应内容:", response.text)
# 运行结果
响应内容: {
"args": {
"currentPage": "2",
"key": "python",
"pageSize": "10"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-681b1fe7-134c8a567302e8a635a65bfa"
},
"origin": "107.175.178.194",
"url": "http://httpbin.org/get?key=python&pageSize=10¤tPage=2"
}
案例:获取历史上的今天
import requests
data = {
"month":5,
"day":7
}
data = {
"month":5,
"day":7
}
response = requests.get("http://www.wudada.online/Api/ScLsDay", params=data)
dict = response.json() # 直接将返回的JSON格式数据解析为字典
print(type(dict))
data = dict.get("data")
print(type(data), data)
for news in data:
print(news)
# 运行结果
<class 'dict'>
<class 'list'> [{'id': '1', 'date': '1602年05月07日', 'title': '中国明代作家李贽逝世'}, {'id': '2', 'date': '1805年05月07日', 'title': '英国首相威廉·佩蒂逝世'}, {'id': '3', 'date': '1812年05月07日', 'title': '英国诗人和编剧罗勃特·勃朗宁出生'}, {'id': '4', 'date': '1840年05月07日', 'title': '俄罗斯作曲家柴科夫斯基出生'}, {'id': '5', 'date': '1861年05月07日', 'title': '印度诗人拉宾德拉纳特·泰戈尔出生'}, {'id': '6', 'date': '1915年05月07日', 'title': '英国卢西塔尼亚号邮轮被击沉'}, {'id': '7', 'date': '1945年05月07日', 'title': '纳粹德国宣布无条件投降'}, {'id': '8', 'date': '1949年05月07日', 'title': '中国共产党革命烈士李白逝世'}, {'id': '9', 'date': '1952年05月07日', 'title': '杰弗里·达默首先发表集成电路概念'}, {'id': '10', 'date': '1967年05月07日', 'title': '香港发生六七暴动'}, {'id': '11', 'date': '1981年05月07日', 'title': '国民革命军陆军中将、著名抗日将领杜聿明逝世'}, {'id': '12', 'date': '1998年05月07日', 'title': '动画片《花木兰》风靡美国'}, {'id': '13', 'date': '1392年05月17日', 'title': '朱元璋所立太子朱标逝世'}, {'id': '14', 'date': '1510年05月17日', 'title': '欧洲文艺复兴早期的画家桑德罗·波提切利逝世'}, {'id': '15', 'date': '1606年05月17日', 'title': '俄国伪沙皇季米特里逝世'}, {'id': '16', 'date': '1727年05月17日', 'title': '俄罗斯帝国女皇叶卡特琳娜一世逝世'}, {'id': '17', 'date': '1749年05月17日', 'title': '牛痘接种爱德华·詹纳出生'}, {'id': '18', 'date': '1846年05月17日', 'title': '阿道夫·萨克斯为萨克斯管取得发明专利'}, {'id': '19', 'date': '1861年05月17日', 'title': '第一张彩色照片在苏格兰皇家学院展出'}, {'id': '20', 'date': '1865年05月17日', 'title': '《国际电报公约》签订,国际电报联盟成立'}, {'id': '21', 'date': '1923年05月17日', 'title': '中国著名生物化学家邹承鲁出生于山东省青岛市'}, {'id': '22', 'date': '1938年05月17日', 'title': '中华民国北洋政府前总统曹锟逝世'}, {'id': '23', 'date': '1947年05月17日', 'title': '香港立法会主席曾钰成出生'}, {'id': '24', 'date': '1948年05月17日', 'title': '国共内战临汾战役结束'}, {'id': '25', 'date': '1971年05月17日', 'title': '荷兰王后马克西玛·索雷吉耶塔出生'}, {'id': '26', 'date': '1984年05月17日', 'title': '我国著名教育家、文学活动家、新文化运动的重要代表成仿吾逝世'}, {'id': '27', 'date': '1995年05月17日', 'title': '波音777正式投入运营'}, {'id': '28', 'date': '1525年05月27日', 'title': '德国农民战争领袖闵采尔逝世'}, {'id': '29', 'date': '1797年05月27日', 'title': '法国革命家、空想共产主义者格拉克斯·巴贝夫逝世'}, {'id': '30', 'date': '1841年05月27日', 'title': '第一次鸦片战争《广州和约》签订'}, {'id': '31', 'date': '1878年05月27日', 'title': '美国舞蹈家伊莎多拉·邓肯出生'}, {'id': '32', 'date': '1897年05月27日', 'title': '英国物理学家约翰·考克饶夫出生'}, {'id': '33', 'date': '1905年05月27日', 'title': '马相伯创立复旦大学前身复旦公学'}, {'id': '34', 'date': '1905年05月27日', 'title': '日本在对马海峡歼灭俄国军舰32艘'}, {'id': '35', 'date': '1910年05月27日', 'title': '德国著名医生和细菌学家罗伯特·科赫逝世'}, {'id': '36', 'date': '1918年05月27日', 'title': '日本内阁总理大臣中曾根康弘出生'}, {'id': '37', 'date': '1919年05月27日', 'title': '美国海军NC-4型水上飞机首次横渡大西洋成功'}, {'id': '38', 'date': '1937年05月27日', 'title': '位于美国的世界著名桥梁金门大桥正式启用'}, {'id': '39', 'date': '1941年05月27日', 'title': '台湾政治人物许信良出生'}, {'id': '40', 'date': '1942年05月27日', 'title': '中国共产党创始人陈独秀逝世'}]
{'id': '1', 'date': '1602年05月07日', 'title': '中国明代作家李贽逝世'}
{'id': '2', 'date': '1805年05月07日', 'title': '英国首相威廉·佩蒂逝世'}
{'id': '3', 'date': '1812年05月07日', 'title': '英国诗人和编剧罗勃特·勃朗宁出生'}
- POST请求
使用requests库内置的post函数发出POST请求,通常在post函数中传入两个参数,第一个必选参数是要访问的URL,第二个可选参数是一个命名参数data,该参数的值会被传输到目标站点服务器,但是不会像GET请求那样将参数拼接到URL之后,而是以form表单的形式提交到服务端。POST
请求这种以提交form表单的方式传输数据的优势是不会将参数暴露在URL中,传输的数据量更大。
# 发送POST请求
data = {
"key": "python",
"version": "3.12",
"date":"2025-05-07"
}
response = requests.post("http://httpbin.org/post", data=data)
print(response.text)
# 运行结果
{
"args": {},
"data": "",
"files": {},
"form": { # 服务端成功接收到表单提交的数据
"date": "2025-05-07",
"key": "python",
"version": "3.12"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "39",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-681b2434-54be552e279987177ad8be79"
},
"json": null,
"origin": "107.175.178.194",
"url": "http://httpbin.org/post"
}
- 添加headers头信息
当使用程序模拟浏览器向服务器发送请求时,需要在请求中添加headers头信息。这样的设置常出现在爬虫程序中,爬虫程序用于从目标网站爬取想要的数据,目标网站为了防止爬虫程序频繁爬取网页数据,通常会将非浏览器发送的请求拦截下来,这时候爬虫程序就需要伪装成浏览器向网站发出请求,爬取有用的数据。
# 参数信息
data = {
"key": "python",
"version": "3.12",
"date":"2025-05-07"
}
# 请求头信息
headers = {
"today": "2025-05-07",
"cookies": '{"token":"12345", "refresh_token": "1234"}',
"haha": "haha"
}
response = requests.post("http://httpbin.org/post", headers=headers, data=data)
response.encoding="utf-8" # 防止中文乱码
print(response.text)
# 运行结果
{
"args": {},
"data": "",
"files": {},
"form": {
"date": "2025-05-07",
"key": "python",
"version": "3.12"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "39",
"Content-Type": "application/x-www-form-urlencoded",
"Cookies": "{\"token\":\"12345\", \"refresh_token\": \"1234\"}",
"Haha": "haha", # 添加的请求头信息
"Host": "httpbin.org",
"Today": "2025-05-07",
"User-Agent": "python-requests/2.31.0",
"X-Amzn-Trace-Id": "Root=1-681b2774-31642fd700d3663f2ac2bc62"
},
"json": null,
"origin": "107.175.178.194",
"url": "http://httpbin.org/post"
}
十二、Python常用拓展库
12.1 Numpy科学计算库
Numpy(即Numerical Python的简称)是Python中的一个基础工具包用以进行科学技术以及数据分析。因此提供了比list向量、list-of-list矩阵性能更好的数组和矩阵,以及常用的数值函数,Numpy被认为是一个高性能的科学计算基础构建。对于其他高级工具库来说Numpy是其构建过程中夯实基础的必备要素。
Numpy中单一数据类型的多维数组以ndarray的形式存储,可以进行快速矢量算术运算。使用底层代码进行数组运算时,标准Python以列表的形式来存储一组数据,但是由于列表中的元素类型不限,可以为任何对象,所有列表保存的是对象的指针。对于一个简单的含有5个数字的数字列表,例如:[1,2,3,4,5]则需要存储5个指针和5个整数对象;如果对整数数据运算时,需要借助循环结构来完成,这样显然比较浪费内存和CPU计算时间。而Numpy提供了对整组数据进行快速运算的标准化数学函数,直接调用即可实现所需功能。
Numpy还可用与磁盘数据的读写以及内存映射文件的操作,实现数据的快速读取与输出,对于多种语言编写的代码,如:C、C++等,使用Numpy也可以做到高效集成。
同时Numpy也是数据分析必不可少的工具,可以进行数据清洗、数据转化等矢量化数组运算,例如:数据排序、合并、分组、标准化、聚合运算等。
12.1.1 Numpy安装
Numpy的安装在命令窗口输入以下命令:
# 安装numpy
python -m pip install numpy
# 导入numpy,方法一
import numpy as np # np作为别名,方便之后的代码书写
# 导入numpy,方法二
from numpy import *
Ananconda中包含了Numpy库,若已安装Anancoda则可直接导入Numpy库
12.1.2 创建ndarray数组
ndarray(N Dimension Array)是一个同构数据N维数组对象,即数组中的所有对象必须是相同类型的,创建ndarray数组可以使用array函数传入Python的序列对象实现。
1.创建一维数组
import numpy as np
a = [1.1, 2.2, 3.3, 4.4]
array = np.array(a)
print("a的类型为: ", type(a))
print("array的类型为: ", type(array))
print("a: {}".format(a))
print("array: {}".format(array))
# 运行结果
a的类型为: <class 'list'>
array的类型为: <class 'numpy.ndarray'>
a: [1.1, 2.2, 3.3, 4.4]
array: [1.1 2.2 3.3 4.4]
2.创建多维数组
如果array函数中传入的是嵌套列表,也就是由多层等长序列嵌套而成的序列,函数将返回一个多维数组。
a = [[1,2,3,4],[5,6,7,8],[2,3,4,5],[6,7,8,9]]
array = np.array(a)
print("a的类型为: ", type(a))
print("array的类型为: ", type(array))
print("a: {}".format(a))
print("array: {}".format(array))
# 运行结果
a的类型为: <class 'list'>
array的类型为: <class 'numpy.ndarray'>
a: [[1, 2, 3, 4], [5, 6, 7, 8], [2, 3, 4, 5], [6, 7, 8, 9]]
array: [[1 2 3 4]
[5 6 7 8]
[2 3 4 5]
[6 7 8 9]]
3.shape函数的使用
Numpy中可以使用shape属性查看每个数组各维度的大小,shape属性的值是一个元组对象。array.shape[0]输出的是第一维的长度,array.shape[1]输出的是第二维的长度,以此类推。
如果数组是一维数组,shape属性值为(n,),n记录数组的长度,也是元素的个数,逗号后面为空,表示该值为元组类型。
如果数组是二维数组,shape属性值为(n1,n2),n1表示行数、n2表示列数,属性值同样是元组对象。
import numpy as np
a = [1.1, 2.2, 3.3, 4.4]
a_array = np.array(a)
b = [[1, 2, 3, 4], [5, 6, 7, 8], [2, 3, 4, 5], [6, 7, 8, 9]]
b_array = np.array(b)
print("a_array shape:{}".format(a_array.shape))
print("b_array shape:{}".format(b_array.shape))
# 运行结果
a_array shape:(4,)
b_array shape:(4, 4)
4.reshape函数
使用Numpy数组中的reshape函数可以更改数组的结构,原数组的shape仍然保持不变。
import numpy as np
a = [[1, 2, 3, 4], [5, 6, 7, 8]]
array = np.array(a)
array_reshape = array.reshape(4,2)
print("array: ")
print(array)
print("array_reshape: ")
print(array_reshape)
print("array: ")
print(array)
# 运行结果
array:
[[1 2 3 4]
[5 6 7 8]]
array_reshape:
[[1 2]
[3 4]
[5 6]
[7 8]]
array:
[[1 2 3 4]
[5 6 7 8]]
注意:array数组依然保持了原来的结构,在新数组array_reshape中各元素在内存中的位置并没有改变,只是改变了每个维度的长度。原数组array和新数组array_reshape共享同一数据存储内存区域,所以对其中一个数组元素的修改,都会同时引起另一个数组内容的改变。
# 更改数组共享内存区域的内容
array[0][0] = 10 # array中第一个元素
print("array: ")
print(array)
print("array_reshape: ")
print(array_reshape)
# 运行结果,对array的修改直接带来了array_reshape中相应元素的改变
array:
[[10 2 3 4]
[ 5 6 7 8]]
array_reshape:
[[10 2]
[ 3 4]
[ 5 6]
[ 7 8]]
5.创建特殊数组
Numpy中定义了一些可以创建特殊数组的函数,如:
- numpy.zeros 创建特定长度、元素都为0的一维或多维数组,可用于数组的初始化
- numpy.ones 创建元素都为1的特定长度数组
- numpy.empty 创建没有具体数值的数组,只需要传入表示数组形状的参数即可,也可以用于数组的初始化
- numpy.arange 类似于Python中的range函数,但是返回值为数组类型
- numpy.eye 创建指定边长和dtype的单位矩阵
import numpy as np
print("zero_array_1: {}".format(np.zeros(5))) # 创建都为0的一维数组
print("zero_array_2: {}".format(np.zeros((3,6)))) # 创建都为0的三行六列数组 传入的shape参数为(3,6),类型为元组
print("one_array: {}".format(np.ones((2,3)))) # 创建都为1的多维数组 传入的shape参数为(2,3),类型为元组
print("empty_array: {}".format(np.empty((2,2,4)))) # 创建没有具体数组的多维数组
print("arange_array: {}".format(np.arange(10))) # 创建指定序列数组
print("eye_array: {}".format(np.eye(3,3))) # 创建单位数组
# 运行结果
zero_array_1: [0. 0. 0. 0. 0.]
zero_array_2: [[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 0. 0.]]
one_array: [[1. 1. 1.]
[1. 1. 1.]]
empty_array: [[[6.23042070e-307 2.11397635e-307 6.23054972e-307 1.06811422e-306]
[3.56043054e-307 1.37961641e-306 1.33507148e-307 8.01097889e-307]]
[[1.78020169e-306 7.56601165e-307 1.02359984e-306 1.42417221e-306]
[1.60218491e-306 1.02360867e-306 1.11261570e-306 2.22522596e-306]]]
arange_array: [0 1 2 3 4 5 6 7 8 9]
eye_array: [[1. 0. 0.]
[0. 1. 0.]
[0. 0. 1.]]
12.1.2 数组的数据类型
数组的数据类型保存在dtype这个特殊对象中,可以使用dtype函数查看
arr = np.array([1.1,2.2,3.3,4.4])
arr1 = np.array([[1,2,3,4], [5,6,7,8]])
print("arr dtype: {}".format(arr.dtype))
print("arr1 dtype: {}".format(arr1.dtype))
# 运行结果
arr dtype: float64
arr1 dtype: int32
在创建ndarray时,dtype作为一个参数可以将一块内存解释为特定的数据类型
arr2 = np.array([1,2,3,4,5], dtype=np.int64)
arr3 = np.array([1,2,3,4,5], dtype=np.float64)
print("arr2: {}, arr2_dtype: {} ".format(arr2,arr2.dtype))
print("arr3: {}, arr3_dtype: {}".format(arr3,arr3.dtype))
# 运行结果
arr2: [1 2 3 4 5], arr2_dtype: int64
arr3: [1. 2. 3. 4. 5.], arr3_dtype: float64
dtype的命名方式为: 类型名 + 元素位长
有符号的整型数值需要占用4个字节,即32位;标准的双精度浮点型数值需要占用8个字节,即64位。所以Numpy中,两种数值分别记作int32和float64。
Numpy支持的数据类型:
| 类型 | 名称 |
|---|---|
| int8,unit8 | 有符号和无符号的8位整型(1个字节) |
| int16,unit16 | 有符号和无符号的16位整型(2个字节) |
| int32,unit32 | 有符号和无符号的32位整型(4个字节) |
| int64,unit64 | 有符号和无符号的64位整型(8个字节) |
| float16 | 半精度浮点数 |
| float32 | 标准的单精度浮点数 |
| flaot64 | 标准的双精度浮点数 |
| complex64,complex128,complex256 | 用两个32位、64位、128位浮点数表示的复数 |
| bool | 布尔类型,True或False |
| object | Python对象类型 |
| string_ | 固定长度的字符串类型(每个字符一个字节) |
| unicode_ | 固定长度的unicode类型 |
对于已经创建好的ndarray,可以使用astype函数转换其数据类型
# 整数型转标准单精度浮点型
arr = np.array([1,2,3,4,5])
arr_float = arr.astype(np.float32)
print("arr: {}, arr_dtype: {} ".format(arr,arr.dtype))
print("arr_float: {}, arr_float_dtype: {} ".format(arr_float,arr_float.dtype))
# 运行结果
arr: [1 2 3 4 5], arr_dtype: int32
arr_float: [1. 2. 3. 4. 5.], arr_float_dtype: float32
# 标准双精度浮点型转整数型 注意:转换成整数的浮点数会将原小数部分全部去掉,而非四舍五入
arr_float = np.array([1.1,2.2,3.3,4.4,5.5])
arr = arr.astype(np.int32)
print("arr_float: {}, arr_float_dtype: {} ".format(arr_float,arr_float.dtype))
print("arr: {}, arr_dtype: {} ".format(arr,arr.dtype))
# 运行结果
arr_float: [1.1 2.2 3.3 4.4 5.5], arr_float_dtype: float64
arr: [1 2 3 4 5], arr_dtype: int32
# 字符串转为数值型
arr_string = np.array(["1.1", "2.2", "3.3", "4.4"], dtype=np.string_)
arr_float = arr_string.astype(np.float64)
print("arr_string: {}, arr_string_dtype: {}".format(arr_string, arr_string.dtype))
print("arr_float: {}, arr_float_dtype: {}".format(arr_float,arr_float.dtype))
# 运行结果
arr_string: [b'1.1' b'2.2' b'3.3' b'4.4'], arr_string_dtype: |S3
arr_float: [1.1 2.2 3.3 4.4], arr_float_dtype: float64
数据类型转换时,Numpy会将Python类型映射到等价的dtype上,所以书写时需要注意,需要在数据类型符号前加np.,例如本例转换为整型需写作np.int32。
12.1.3 数组的索引与切片
索引和切片都是根据条件对数组袁术进行存取的方法。索引是获取数据中特殊位置元素的过程,可以通过数据的标识,轻松地访问指定数据。切片是获取数组元素子集的过程,通过索引值截取索引片段,获得一个新的独立数组。Numpy中提供了对数组进行索引和切片处理的方法。
1.一维数组索引
一维Numpy数组的索引与切片方法基本和列表一致。
索引: arr[索引]
切片: arr[开始:结束后一位]
# 一维Numpy数组索引和切片
arr = np.arange(15)
print("arr: {}".format(arr))
print("arr[8]: {}", arr[8])
print("arr[8:12]: {}".format(arr[8:12]))
# 使用索引与切片对原Numpy数组进行修改
arr[8:12] = 30
print("arr: {}".format(arr))
arr[9] = 9
print("arr: {}".format(arr))
Numpy数组与列表切片的不同之处在于,数组切片的操作对象不是副本,而是原始数组视图,也就是对于视图上的所有修改,原数组都会随之改变,而数据不会被赋值。所有,Numpy可以用于处理数据量较大的数据集,减少因复制数据带来的内存和性能问题。如果不希望修改原数据,需要做显式复制操作,可以使用copy函数。
# 显式复制
arr = np.arange(15)
arr_origin = arr.copy()
arr[8:12] = 30
print("arr: {}".format(arr))
print("arr_origin: {}".format(arr_origin))
# 运行结果
arr: [ 0 1 2 3 4 5 6 7 30 30 30 30 12 13 14]
arr_origin: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
如果希望原数组与修改后的数组同时保存,则需要将原数组保存为一份副本。
2.二维数组索引
对于二维数组,每个索引位置上对应的元素不再是标量,而是一维数组。
# 获取一维数组
arr_2d = np.array([[1,1,1],[2,2,2],[3,3,3]])
print("arr_2d[1]: {}".format(arr_2d[1]))
# 运行结果
arr_2d[1]: [2 2 2]
# 获取具体元素
print("arr_2d[2,1]: {}".format(arr_2d[2,1]))
print("arr_2d[2][1]: {}".format(arr_2d[2][1]))
# 运行结果
arr_2d[2,1]: 3
arr_2d[2][1]: 3
3.多维数组索引
对于多维数组的索引,返回对象为降低维度之后的ndarray
# 多维数组索引
arr_3d = np.arange(16).reshape((2,2,4)) # 创建一个三维数组
print("arr_3d: {}".format(arr_3d)) # 2*(2*4)
print("arr_2d: {}".format(arr_3d[0])) # 2*4
print("arr_1d: {}".format(arr_3d[0][0])) # 4
print("arr_3d[0,0,0]: {}".format(arr_3d[0,0,0]))
# 运行结果
arr_3d: [[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
arr_2d: [[0 1 2 3]
[4 5 6 7]]
arr_1d: [0 1 2 3]
arr_3d[0,0,0]: 0
# 使用索引来修改数组中元素数值
arr_3d_origin = arr_3d[0].copy()
arr_3d[0] = 50
print("arr_3d_origin: {}".format(arr_3d_origin))
print("arr_3d: {}".format(arr_3d))
arr_3d[0] = arr_3d_origin
print("arr_3d: {}".format(arr_3d))
# 运行结果
arr_3d_origin: [[0 1 2 3]
[4 5 6 7]]
arr_3d: [[[50 50 50 50]
[50 50 50 50]]
[[ 8 9 10 11]
[12 13 14 15]]]
arr_3d: [[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]]
4.切片索引
ndarray的切片索引只需要将数组中的每一行每一列都分别看作一个列表,参照列表切片索引的办法,最终返回数组类型的数据。
# 多维数组切片索引
arr_2d = np.arange(25).reshape(5,5)
print("arr_2d: {}".format(arr_2d))
print("arr_2d[1,2:4]: {}".format(arr_2d[1,2:4])) # 取出第二行,索引为2、3的数字7、8
print("arr_2d[1:3,2:4]: {}".format(arr_2d[1:3,2:4])) # 取出行索引为1、2,列索引为2、3的二维数组
print("arr_2d[:,2:]: {}".format(arr_2d[:,2:])) # 取出第三列之后的二维数组
print("arr_2d[::2,2:]: {}".format(arr_2d[::2,2:])) # 行方向隔行取数,列方向取第三列之后的二维数组
# 运行结果
arr_2d: [[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
arr_2d[1,2:4]: [7 8]
arr_2d[1:3,2:4]: [[ 7 8]
[12 13]]
arr_2d[:,2:]: [[ 2 3 4]
[ 7 8 9]
[12 13 14]
[17 18 19]
[22 23 24]]
arr_2d[::2,2:]: [[ 2 3 4]
[12 13 14]
[22 23 24]]
注意:arr[行索引开始:行索引结束:行索引增加步长, 列索引开始:列索引结束:列索引增加步长]
5.布尔型索引
布尔型数据作为数组的索引时,会根据布尔数组的True或False值筛选对于轴上的数据。
布尔索引不仅可以设置正向条件,还可用设置反向条件
- != 不等于
- ~ 表示对于条件的否定
- logical_not 函数用于设置反向条件
# 使用布尔型数据作为数组的索引
arr_2d = np.arange(25).reshape(5,5)
x = np.array([0,1,2,3,1])
print(x==1)
# 运行结果
[False True False False True]
# 选定布尔值为True的行,注意布尔数组的长度必须与原索引数组的行数相同
print("arr_2d[x==1]: {}".format(arr_2d[x==1]))
# 运行结果
arr_2d[x==1]: [[ 5 6 7 8 9]
[20 21 22 23 24]]
# 布尔索引与切片结合使用
print("arr_2d[x==1,2:]: {}".format(arr_2d[x==1,2:]))
# 运行结果
arr_2d[x==1,2:]: [[ 7 8 9]
[22 23 24]]
# 布尔型反向索引
print("arr_2d[x!=1]: {}".format(arr_2d[x!=1]))
print("arr_2d[~(x==1)]: {}".format(arr_2d[~(x==1)]))
print("arr_2d[np.logical_not(x==1)] = {}".format(arr_2d[np.logical_not(x==1)]))
# 运行结果
arr_2d[x!=1]: [[ 0 1 2 3 4]
[10 11 12 13 14]
[15 16 17 18 19]]
arr_2d[~(x==1)]: [[ 0 1 2 3 4]
[10 11 12 13 14]
[15 16 17 18 19]]
arr_2d[np.logical_not(x==1)] = [[ 0 1 2 3 4]
[10 11 12 13 14]
[15 16 17 18 19]]
布尔运算符“&”、“|”可用于设置多个布尔条件,多条件选择所需要的数组
# 多个布尔条件索引
print("arr_2d[(x==1) | (x==0)]: {}".format(arr_2d[(x==1)|(x==0)]))
# 运行结果
arr_2d[(x==1) | (x==0)]: [[ 0 1 2 3 4] # x==0
[ 5 6 7 8 9] # x==1
[20 21 22 23 24]] # x==1
# 使用布尔索引,将数组中满足条件的所有元素都筛选出来并修改其值
# 将数组中所有大于10的数据都修改为10
print("arr_2d: {}".format(arr_2d))
arr_2d[arr_2d>10] = 10
print("arr_2d: {}".format(arr_2d))
# 运行结果
arr_2d: [[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
arr_2d: [[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 10 10 10 10]
[10 10 10 10 10]
[10 10 10 10 10]]
12.1.4 数学与统计函数调用
1.统计计算
Numpy提供了一些数学函数,可以直接对整个数组或者某个轴向上的数据进行数学统计计算。比如求和公式(sum)、求平均值(mean)、方差(var)、标准差(std)、最大值(max)、最小值(min)、累计和(cumsum)与积(cumprod)、最大最小元素的索引(argmax、argmin)等。
# Numpy统计计算
arr = np.arange(25).reshape(5,5)
print("arr.sum(): {}".format(arr.sum())) # 对所有元素求和
print("arr.mean(): {}".format(arr.mean())) # 求所有元素的均值
print("arr.std(): {}".format(arr.std())) # 求所有元素的标准差
print("arr.var(): {}".format(arr.var())) # 求所有元素的方差
print("arr.max(): {}".format(arr.max())) # 求所有元素中的最大值
print("arr.argmax(): {}".format(arr.argmax())) # 求所有元素中中最大元素的索引
print("arr.min(): {}".format(arr.min())) # 求所有元素中的最小值
print("arr.argmin(): {}".format(arr.argmin())) # 求所有元素中最小元素的索引
print("arr.cumsum(): {}".format(arr.cumsum())) # 求所有元素的累计和
print("arr.cumprod(): {}".format(arr.cumprod())) # 求所有元素的累计积
# 运行结果
arr.sum(): 300
arr.mean(): 12.0
arr.std(): 7.211102550927978
arr.var(): 52.0
arr.max(): 24
arr.argmax(): 24
arr.min(): 0
arr.argmin(): 0
arr.cumsum(): [ 0 1 3 6 10 15 21 28 36 45 55 66 78 91 105 120 136 153
171 190 210 231 253 276 300]
arr.cumprod(): [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
2.矩阵运算
Numpy中的二维数组可以被看作是矩阵,矩阵运算对于的是元素量级,Numpy中定义了一些矩阵运算的相关函数,比如矩阵的转置函数(.T)、矩阵的点乘(.dot)、矩阵的迹(trace)等。可以快速地对整个矩阵数据进行操作。
# 1.矩阵的转置
arr = np.array([[1,2,3],[4,5,6],[7,8,9]])
print("arr: {}".format(arr))
print("arr.T: {}".format(arr.T))
# 运行结果
arr: [[1 2 3]
[4 5 6]
[7 8 9]]
arr.T: [[1 4 7]
[2 5 8]
[3 6 9]]
# 2.矩阵的逆
# 矩阵的逆通过使用np.linalg.inv函数获得
print("arr_1: {}".format(np.linalg.inv(arr)))
# 运行结果 抛出异常,输入的矩阵为奇异矩阵(arr行列式值为0)
raise LinAlgError("Singular matrix")
numpy.linalg.LinAlgError: Singular matrix
# 非奇异矩阵,行列式值不为0
arr = np.array([[1,2,3],[4,5,6],[7,8,0]])
print("arr_1: {}".format(np.linalg.inv(arr)))
# 运行结果
arr_1: [[-1.77777778 0.88888889 -0.11111111]
[ 1.55555556 -0.77777778 0.22222222]
[-0.11111111 0.22222222 -0.11111111]]
# 3.矩阵的加减法
arr2 = np.array([[2,3,4],[3,4,5],[4,5,6]])
print("arr + arr2: {}".format(arr+arr2))
print("arr - arr2: {}".format(arr-arr2))
# 运行结果
arr + arr2: [[ 3 5 7]
[ 7 9 11]
[11 13 6]]
arr - arr2: [[-1 -1 -1]
[ 1 1 1]
[ 3 3 -6]]
# 4.矩阵的乘法和矩阵的点乘
# 矩阵的乘法是第m行乘第n列得到(m,n)位置处元素,Numpy中计算矩阵乘法:A.dot(B.T)
# 矩阵的点乘是两个结构相同的矩阵对应元素相乘,从而得到一个新的矩阵, Numpy中计算矩阵点乘:A*B
print("矩阵arr点乘arr2: {}".format(arr*arr2))
print("矩阵arr乘arr2: {}".format(arr.dot(arr2.T)))
# 运行结果
矩阵arr点乘arr2: [[ 2 6 12]
[12 20 30]
[28 40 0]]
矩阵arr乘arr2: [[20 26 32]
[47 62 77]
[38 53 68]]
# 5.矩阵的迹
# 在线性代数中,矩阵的迹为主对角线上个元素的总和。Numpy中使用函数np.trace来获得矩阵的迹
print("arr的迹: {}".format(np.trace(arr)))
# 运行结果
arr的迹: 6
# 6.特征值、特征向量
# 如果一个矩阵A是n阶方阵,存在常数m和非零n维向量x,使得Ax=mx,那么称m是矩阵A的一个特征值,向量x为特征值m对应的特征向量
eigvalue,eigvector = np.linalg.eig(arr)
print("arr特征值为: {}".format(eigvalue))
print("arr特征向量为: {}".format(eigvector))
# 运行结果
arr特征值为: [12.12289378 -0.38838384 -5.73450994]
arr特征向量为: [[-0.29982463 -0.74706733 -0.27625411]
[-0.70747178 0.65820192 -0.38842554]
[-0.63999131 -0.09306254 0.87909571]]
3.数据处理
Numpy数组中的数据呈现有时候可能有别于项目研究的目标,需要进行数据处理。Numpy提供了一些对ndarray进行直接处理的函数。
# 1.矩阵排序 np.sort函数返回的是已排序的副本,不对原数组做改变。
# 使用Numpy中的sort函数可以对数组做排序处理,当函数中的参数axis=0时,每一列上的元素按照行的方向排序,axis=1时,每一行的元素按照列的方向排序
arr = np.array([[2,5,1],[6,3,6],[7,3,6]])
print("arr排序前: {}".format(arr))
arr_sort_row = np.sort(arr,axis=1)
print("arr排序后: {}".format(arr))
print("按行排序后arr_sort_row: {}".format(arr_sort_row))
arr_sort_column = np.sort(arr,axis=0)
print("arr排序后: {}".format(arr))
print("按列排序后arr_sort_column: {}".format(arr_sort_column))
# 运行结果
arr排序前: [[2 5 1]
[6 3 6]
[7 3 6]]
arr排序后: [[2 5 1]
[6 3 6]
[7 3 6]]
按行排序后arr_sort_row: [[1 2 5]
[3 6 6]
[3 6 7]]
arr排序后: [[2 5 1]
[6 3 6]
[7 3 6]]
按列排序后arr_sort_column: [[2 3 1]
[6 3 6]
[7 5 6]]
# 2.去重
# Numpy中提供了对一维数组去重的函数unique,该函数的返回值为数组中按照从小到大的顺序排列的非重复元素的元组或列表。
arr = np.array([1,4,5,2,6,2,5,2,1,3,5,2,2])
print("去重后的元素: {}".format(np.unique(arr)))
# 运行结果
去重后的元素: [1 2 3 4 5 6]
12.1.5 Numpy文件读入和读出
在数据挖掘中,通常需要调用以文件形式存储的数据,同时也可能需要把数据写入文件中。Numpy提供了文件写入和读取的函数savetxt和loadtxt以实现这两个功能。
# 1.写入文件操作
arr=np.arange(9).reshape(3,3)
np.savetxt("arr.txt",arr)
# 2.读取数据文件
arr1 = np.loadtxt("arr.txt")
print("文件内容: {}".format(arr1))
# 运行结果
文件内容: [[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
# 3.写入数据到csv文件中
# 创建一个3行4列的随机数组
arr = np.random.rand(3, 4)
# 保存数组为csv文件
np.savetxt('arr.csv', arr, delimiter=',')
# 4.从csv文件中读取数据
arr1 = np.loadtxt("arr.csv", delimiter=',')
print("文件内容: {}".format(arr1))
12.1.6 广播
1.广播机制
广播 (Broadcast) 是 NumPy 对不同形状 (shape) 的数组进行数值计算的一种方式。它允许对形状不同的数组进行算术运算,通常矩阵数值计算都是在相应的元素上进行。当两个数组的形状相同时,即满足 a.shape == b.shape,那么 a * b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。例如:
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([10, 20, 30, 40])
c = a * b
print(c)
但Numpy中,形状不同的数组之间也可以进行运算。如矩阵乘一个标量(单一数值),其效果是矩阵中每个元素都乘以标量。在这个过程中标量先被扩展成矩阵再与之前的矩阵进行乘法运算。
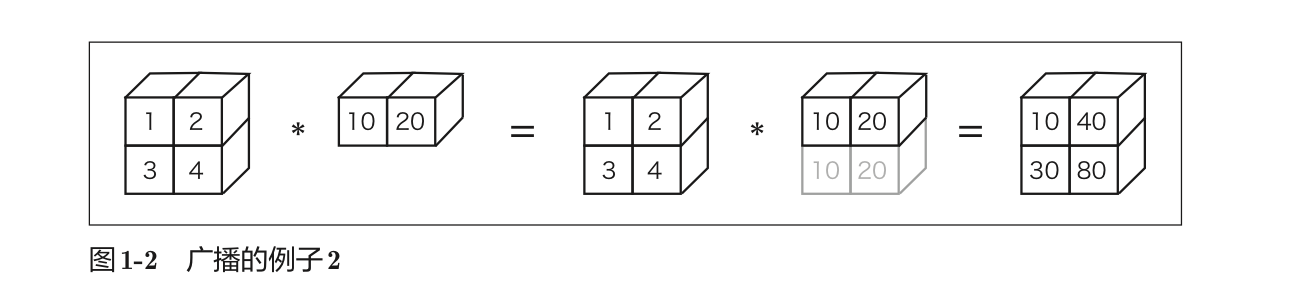
但是不是任意的数组都能广播
# 不是任意的数组都能广播
arr = np.array([[1,2,3],[2,3,4],[3,4,5]])
arr1 = np.array([1,2])
print(arr*arr1)
# 运行结果
ValueError: operands could not be broadcast together with shapes (3,3) (2,)
2.广播规则
广播机制遵循以下规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分通过在前面加 1 补齐。
a = np.array([[0],[1],[2]])
b = np.arange(3)
print("a.shape: {}".format(a.shape))
print("b.shape: {}".format(b.shape))
# 运行结果
a.shape: (3, 1)
b.shape: (3,) # “形状中不足的部分通过在前面加 1 补齐”的意思是数组在该维度不存在,将该维度视为1,并且把1放到shape元组的前面,即将b的形状视为(1,3)
- 输出数组的形状是输入数组形状的各个维度上的最大值。
# 由规则1可知,现在a.shape=(3,1),b.shape=(1,3)
# 由规则2可知输出数组的形状是输入数组形状各个维度的最大值,那么输出数组行维度应为3,列维度应为3。因此a.shape应拓展为(3,3) b.shape 因拓展为(3,3)
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值。(数据拓展规则)
# 形状
a.shape: (3, 1)
b.shape: (3,) # 由规则1视为(1,3)
# 若a+b,则a、b都要拓展到(3,3),拓展方向为维度为1的方向
# a的列维度为1,所以a向列扩展,b的行维度为1,所以b向行拓展
# a拓展后变成[[0,0,0],[1,1,1],[2,2,2]] ,b拓展后变成[[0,1,2],[0,1,2],[0,1,2]]
# 通过广播机制后a,b形状相同,可以计算
print(a+b)
# 运算结果
[[0 1 2]
[1 2 3]
[2 3 4]]
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错。
a = np.arange(9).reshape(3,3)
b = np.arange(4).reshape(2,2)
# 假设a、b可以相加,c=a+b,则c的每个维度值应该是输入数组中每个维度最大的值,即为(3,3),显然b的各个维度与输出数组对应维度的长度不相等,且长度不为1,所以a、b不能相加
a = np.arange(9).reshape(3,3)
b = np.arange(2).reshape(2,1)
# 假设a、b可以相加,c=a+b,则c的每个维度值应该是输入数组中每个维度最大的值,即为(3,3),b列维度与输出数组列维度的长度不相等,但长度为1,暂时可以,接着继续分析,b的行维度为2,与输出数组行维度不等,且不为1,所以a、b不能相加
对于广播规则另一种简单理解:
将两个数组的维度大小右对齐,然后依次比较对应维度上的数值,如果数值相等或其中有一个为1或为空,每个维度都能满足这个条件,则能进行广播运算,否则不能进行广播运算。
3.广播的作用
NumPy的广播机制是数组运算的核心特性之一,其作用主要体现在以下5个方面:
- 消除冗余循环,提升执行效率
广播允许NumPy在底层用向量化C代码直接处理不同形状的数组运算,无需用户手动编写嵌套循环。例如:
# 未使用广播时(低效的显式循环)
result = []
for i in range(3):
row = []
for j in range(2):
row.append(arr[i] + b[j])
result.append(row)
# 使用广播时(高效隐式运算)
arr = np.array([[1,2], [3,4], [5,6]]) # 形状 (3,2)
b = np.array([10, 20]) # 形状 (2,)
print(arr + b) # 直接输出 [[11,22], [13,24], [15,26]]
- 零内存拷贝,节省计算资源
广播通过维度扩展模拟运算,而非创建物理副本。例如将标量 5 加到数组时:
arr = np.array([1,2,3])
arr + 5 # 实际运算等价于 arr + [[5], [5], [5]],但不会复制数据
内存中始终只保留原始数组,广播通过数学技巧虚拟扩展维度。
- 简化复杂运算的代码表达
-
标量与数组混合运算:
arr = np.array([[1,2], [3,4]]) arr * 2.5 # 等效于 arr * [[2.5, 2.5], [2.5, 2.5]] -
不同维度数组对齐:
a = np.array([1,2,3]) # 形状 (3,) b = np.array([[4], [5], [6]]) # 形状 (3,1) a + b # 输出 [[5,6,7], [6,7,8], [7,8,9]]
- 支持高维数据的批量处理
在机器学习和科学计算中,广播可高效处理批量任务:
# 批量矩阵加法(假设有100个3x3矩阵)
batch_matrices = np.random.rand(100, 3, 3)
bias = np.random.rand(3, 3) # 单个偏置矩阵
result = batch_matrices + bias # 自动广播到所有100个矩阵
- 实现灵活的数学运算抽象
广播规则使得数学公式可以更直观地映射到代码:
# 计算三维点到原点的距离(假设有N个点)
points = np.random.rand(N, 3)
distances = np.sqrt(np.sum(points**2, axis=1)) # 向量化实现
4. 广播的典型应用场景
| 场景 | 代码示例 | 等效操作 |
|---|---|---|
| 图像批量处理 | images + mean_image |
对每张图像减去均值 |
| 参数广播 | weights * input_batch |
权重矩阵与批量输入相乘 |
| 坐标系变换 | points + translation_vector |
对所有点应用平移变换 |
| 概率计算 | probabilities * class_weights |
带权重的类别概率计算 |
5.性能对比
| 操作 | 广播耗时 | 显式循环耗时 | 加速比 |
|---|---|---|---|
| 1000x1000矩阵加法 | 0.8ms | 1200ms | 1500× |
| 100万元素标量乘法 | 0.5ms | 80ms | 160× |
(测试环境:Intel i7-12700H,数据为近似值)[数据来源——文心一言]
通过消除Python层的循环开销,广播机制使得NumPy比纯Python代码快2-3个数量级,这是科学计算库选择NumPy作为底层引擎的核心原因之一。
12.2 Pandas数学分析库
Pandas是一个用于处理高级数据结构和数据分析的Python库。Pandas是基于Numpy构建的一种工具,纳入了大量模块和一些标准的的数据模型,提供了Python处理大数据的性能。
Pandas具有以下一些特点:
- Dataframe是一种高效快速的数据结构对象,Pandas支持Dataframe格式,从而可以自定义索引
- 可以将不同格式的数据文件加载到内存中
- 未对齐及索引方式不同的数据可按轴自动对齐
- 可处理时间序列或非时间序列数据
- 可基于标签来切片索引,获得大数据集子集
- 可进行高性能数据分组、聚合、添加、删除
- 灵活处理数据缺失、重组、空格
Pandas广泛应用于金融、经济、数据分析、统计等商业领域,为各领域数据从业者提供了便捷。
12.2.1 Pandas安装
# Pandas安装命令
pip install pandas
# 导入pandas
import pandas as pd
如果已经安装Anancoda可以直接将其导入
12.2.2 Pandas数据结构
Pandas中被广泛使用的数据结果主要有Series和DataFrame,两者为Python进行数据存储和分析提供基础。
1.Series
(1)创建Series
Series类似于一维数组,可由一组数据产生。Series数组由数据与其索引标签组成,索引在左侧,值在右侧。创建Series可以使用Series函数。
import pandas as pd
# 创建Series数组
s1 = pd.Series([1,2,3,4,5])
print("s1: {}".format(s1))
print("s1.type: {}".format(type(s1)))
# 运行结果
s1: 0 1
1 2
2 3
3 4
4 5
dtype: int64
s1.type: <class 'pandas.core.series.Series'>
Series默认创建一个从0到数据长度减1的整数型索引。如果希望更改索引对象,可在数组创建时设置index参数。
s2 = pd.Series([1,2,3,4,5],index=["第一","第二","第三","第四","第五"])
print("s2: {}".format(s2))
# 运行结果
s2: 第一 1
第二 2
第三 3
第四 4
第五 5
dtype: int64
(2)Series的索引和切片
通过Series的value和index属性可获取Series中的索引和数值
print("s2 索引:{}".format(s2.index))
print("s2 值: {}".format(s2.values))
# 运行结果
s2 索引:Index(['第一', '第二', '第三', '第四', '第五'], dtype='object')
s2 值: [1 2 3 4 5]
每一个数组都有与之相对应的索引,所以在Series中,可以通过索引的方式选取或修改Series的数值
注意:index对象是不可以修改的,尝试修改会报错,这样才能保障index对象可以安全地在多个数据结构中共享
# Series的索引
print("s2中 第二 对应的数值: {}".format(s2["第二"]))
s2["第二"] = 10
print("s2中 第二 对应的数值: {}".format(s2["第二"]))
# 运行结果
s2中 第二 对应的数值: 2
s2中 第二 对应的数值: 10
# Series索引多个数值
print("s2中 第二、第三、第四 对应的数值: {}".format(s2[["第二","第三","第四"]]))
# 运行结果
s2中 第二、第三、第四 对应的数值: 第二 10
第三 3
第四 4
dtype: int64
# Series连续索引
print("s2中 第二到第五 对应的数值: {}".format(s2["第二":"第五"]))
# 运行结果
s2中 第二到第五 对应的数值: 第二 10
第三 3
第四 4
第五 5
dtype: int64
# 注意:这里的切片与Python切片稍有不同,Series切片末端元素是包含在内的,所以,索引“第五”对应的数值会被输出
(3)字典类型创建Series
# 字典类型数据创建Series
# Python中的字典格式数据可以直接用来创建Series
s_dic = {'First':1, 'Second':2, 'Third':3, 'Four':4, 'Five':5}
s3 = pd.Series(s_dic)
print("s3: {}".format(s3))
# 运行结果
s: First 1
Second 2
Third 3
Four 4
Five 5
dtype: int64
# 判断元素是否存在与Series中
print('s3中含有 six:{}'.format('six' in s3))
print('s3中不含six: {}'.format('six' not in s3))
# 运行结果
s3中含有 six:False
s3中不含six: True
# 判断是否存在缺失值
# 如果传入的index参数中含有原字典不含有的索引标签,那么索引参数与数据字典value值,无法匹配成功。为匹配成功的index对应的数值位置就记录为空,用NaN来表示,代表缺失值。可用isnull或notnull函数判断是否存在缺失值。
dic_s = {'First':1, 'Second':2, 'Third':3, 'Fourth':4, 'Fifth':5}
s4 = pd.Series(dic_s, index=['First', 'Second', 'Third', 'Fourth', 'Tenth' ])
print("s4: {}".format(s4))
# 运行结果
s4: First 1.0
Second 2.0
Third 3.0
Fourth 4.0
Tenth NaN # Tenth无对应value值
dtype: float64
# 检查对应key值是否为空
print("数据缺失: {}".format(s4.isnull()))
print("数据不缺失: {}".format(s4.notnull()))
# 运行结果
数据缺失: First False
Second False
Third False
Fourth False
Tenth True
dtype: bool
数据不缺失: First True
Second True
Third True
Fourth True
Tenth False
dtype: bool
(4)Series的算术运算
不同的Series数组间可以做算术运算,在算术运算中,不同索引对应的数据会自动对齐,相同索引的数据实现算术运算
s_dic1 = {'First':1, 'Second':2, 'Third':3, 'Fourth':4, 'Fifth':5}
s3 = pd.Series(s_dic1)
dic_s2 = {'First':1, 'Second':2, 'Third':3, 'Fourth':4, 'Fifth':5}
s4 = pd.Series(dic_s2, index=['First', 'Second', 'Third', 'Fourth', 'Tenth' ])
print('s3 + s4 = {}'.format(s3 + s4))
# 运行结果
s3 + s4 = Fifth NaN # s4索引中无'Fifth'索引
First 2.0
Fourth 8.0
Second 4.0
Tenth NaN # s3中无'Tenth'索引
Third 6.0
dtype: float64
2. DataFrame数据结构
DataFrame是Pandas中的一种数据结构,它是二维表格型数据结构,既含有行索引,又含有列索引。每一列的数据可以是不同类型的数据。
(1)创建DataFrame
# 使用字典创建DataFrame, 注意长度要一致,否则会报错
df_dic ={'color':['red', 'yellow', 'green', 'pink', 'black'], 'size': ['small', 'medium', 'big', 'meidum big', 'super big'], 'taste': ['sweet', 'sour', 'salty', 'spicy', 'spicy']}
df = pd.DataFrame(df_dic)
print("df :{}".format(df))
print("df的类型为: {}".format(type(df)))
# 运行结果
df : color size taste
0 red small sweet
1 yellow medium sour
2 green big salty
3 pink meidum big spicy
4 black super big spicy
df的类型为: <class 'pandas.core.frame.DataFrame'>
# 设置列排序
df1 = pd.DataFrame(df_dic, columns=['taste', 'color', 'size', 'category'])
print("df1: {}".format(df1))
# 运行结果
df1: taste color size category # columns中含有'category'的列名,与原字典key值不匹配,该列被记作NaN列
0 sweet red small NaN
1 sour yellow medium NaN
2 salty green big NaN
3 spicy pink meidum big NaN
4 spicy black super big NaN
# 设置表头的列名称的标题和行名称的标题
df1.index.name = 'sample'
df1.columns.name = 'feature'
print("df1: {}".format(df1))
# 运行结果
df1: feature taste color size category
sample
0 sweet red small NaN
1 sour yellow medium NaN
2 salty green big NaN
3 spicy pink meidum big NaN
4 spicy black super big NaN
# 使用values函数获取DataFrame中的所有数据,以二维数组的形式返回
print("df1的values值为: {}".format(df1.values))
# 运行结果
df1的values值为: [['sweet' 'red' 'small' nan]
['sour' 'yellow' 'medium' nan]
['salty' 'green' 'big' nan]
['spicy' 'pink' 'meidum big' nan]
['spicy' 'black' 'super big' nan]]
(2)DataFrame的索引
# 获取DataFrame中的列
print("df1中的color列: {}".format(df1['color']))
print("df1中的color列: {}".format(df1.color))
# 运行结果
df1中的color列: sample
0 red
1 yellow
2 green
3 pink
4 black
Name: color, dtype: object
df1中的color列: sample
0 red
1 yellow
2 green
3 pink
4 black
Name: color, dtype: object
# 获取DataFrame的行
print('df1中行序号为3: {}'.format(df1.loc[3]))
print('df1中列索引为color,且行序号为3: {}'.format(df1.loc[3, 'color']))
# 基于整数位置的索引
print("df1在(3,1)位置处的元素: {}".format(df1.iloc[3][1]))
# 运行结果
df1中行序号为3: feature
taste spicy
color pink
size meidum big
category NaN
Name: 3, dtype: object
df1中列索引为color,且行序号为3: pink
df1在(3,1)位置处的元素: pink
通过DataFrame数据的索引,对特定数组进行修改
# 修改category列
df1['category'] = np.arange(5)
print(df1)
# 运行结果
feature taste color size category
sample
0 sweet red small 0
1 sour yellow medium 1
2 salty green big 2
3 spicy pink meidum big 3
4 spicy black super big 4
# 如果只希望填充特定部分数值,可精确匹配DataFrame中缺失值的索引,然后填补缺失值
df1['category'] = pd.Series([2, 4, 6], index=[0, 2, 4])
print(df)
# 运行结果
feature taste color size category
sample
0 sweet red small 2.0
1 sour yellow medium NaN
2 salty green big 4.0
3 spicy pink meidum big NaN
4 spicy black super big 6.0
# 为不存在的的列赋值将会创建一个新的列
df1.country = pd.Series(['China', 'USA', 'UK', 'Australia', 'Japan'])
print(df1)
# 运行结果
UserWarning: Pandas doesn't allow columns to be created via a new attribute name - see https://pandas.pydata.org/pandas-docs/stable/indexing.html#attribute-access
df1.country = pd.Series(['China', 'USA', 'UK', 'Australia', 'Japan'])
# 为不存在的的列赋值将会创建一个新的列
df1['country'] = pd.Series(['China', 'USA', 'UK', 'Australia', 'Japan'])
print(df1)
# 运行结果
feature taste color size category country
sample
0 sweet red small 2.0 China
1 sour yellow medium NaN USA
2 salty green big 4.0 UK
3 spicy pink meidum big NaN Australia
4 spicy black super big 6.0 Japan
# 使用布尔型数组进行索引
print('df1中 category小于等于3的样本数据 :{}'.format(df1[df1['category']<=3]))
# 运行结果
df1中 category小于等于3的样本数据 :feature taste color size category country
sample
0 sweet red small 2.0 China
12.2.3 数学与统计计算
Pandas提供了对Series和DataFrame进行汇总统计的函数,比如求和、求平均数、求分位数等
1. 求和
# 求和
df = pd.DataFrame([[3, 2, 3, 1], [2, 3, 4, 5], [1, 6, 3, 2], [3, 5, 6, 1]], index=['a', 'b', 'c', 'd'], columns=['one', 'two', 'three', 'four'])
print("df: {}".format(df))
print("df.sum 按列求和: {}".format(df.sum()))
print("df.sum 按行求和: {}".format(df.sum(axis=1)))
# 运行结果
df: one two three four
a 3 2 3 1
b 2 3 4 5
c 1 6 3 2
d 3 5 6 1
df.sum 按列求和: one 9
two 16
three 16
four 9
dtype: int64
df.sum 按行求和: a 9
b 14
c 12
d 15
dtype: int64
print("df.cumsum 从上到下累计求和: {}".format(df.cumsum()))
print("df.cumsum 从左到右累计求和: {}".format(df.cumsum(axis=1)))
# 运行结果
df.cumsum 从上到下累计求和:
one two three four
a 3 2 3 1
b 5 5 7 6
c 6 11 10 8
d 9 16 16 9
df.cumsum 从左到右累计求和:
one two three four
a 3 5 8 9
b 2 5 9 14
c 1 7 10 12
d 3 8 14 15
2. 常用统计函数
| 统计函数 | 解释 |
|---|---|
| mean | 均值 |
| median | 中位数 |
| count | 非缺失值数量 |
| min、max | 最小最大值 |
| describe | 汇总统计 |
| var | 方差 |
| std | 标准差 |
| skew | 偏度 |
| kurt | 峰度 |
| diff | 一阶差分(一阶导数) |
| cumin、cummax | 累计最小值、累计最大值 |
| cumsum、cumprod | 累计和、累计积 |
| cov、corr | 协方差、相关系数 |
12.2.3 DataFrame的文件操作
1. 读取文件
Pandas中常用读取数据文件函数
| 读取数据文件函数 | 解释 |
|---|---|
| pd.read_csv(filename) | 从csv文件导入数据,默认分隔符为‘,’ |
| pd.read_table(filename) | 从文本文件中导入数据,默认分隔符为制表符 |
| pd.read_excel(filename) | 从Excel中导入数据 |
| pd.read_sql(query, connection_object) | 从SQL表、库中导入数据 |
| pd.read_json(json_string) | 从json文件中导入数据 |
| pd_read_html(url) | 解析URL、字符串或者HTML文件,提取表格数据 |
| pd.DataFrame(dict) | 从字典对象中导入数据 |
Pandas读取csv格式文件
# Pandas读取csv格式文件
pd.read_csv('df.csv', encoding='utf-8')
2. 写入文件
Pandas中常用写入文件函数
| 写入文件函数 | 解释 |
|---|---|
| df.to_csv(filename) | 导出数据至csv文件 |
| df.to_excel(filename) | 导出数据至Excel文件 |
| df.to_sql(table_name, connection_object) | 导出数据至SQL表 |
| df.to_json(filename) | 导出数据为json格式 |
| df.to_html(filename) | 导出数据为html文件 |
| df.to_clipboard(filename) | 导出数据到剪贴板中 |
Pandas写入csv格式文件
# Pandas写入数据到csv文件
df.to_csv('df.csv', sep=',', header=True, index=True, encoding="utf-8")
12.2.4 数据处理
在做数据分析时,读取的数据有时不符合数据分析的要求,可能会存在一些缺失值、重复值等,Pandas提供了对Series数组和DataFrame进行数据预处理(数据清洗)的方法。
1. 缺失值处理
缺失值在数据中的表现主要有三种:
- 不存在型空值,也就是无法获取的值。比如未婚人士的配偶姓名
- 存在型空值,样本的该特征是存在的,但是暂时无法获取数据,之后该信息一旦被确定,就可以补充数据,使信息趋于完整
- 占位型空值,无法确定是不存在型空值还是存在型空值,得随着时间的推移来确定,是不确定的
(1)查找空缺值
Pandas可以使用isnull函数来判断是否存在缺失值。DataFrame中的缺失值一般记作:numpy.nan,表示数据空缺
# 查找DataFrame中的空缺值
df = pd.DataFrame([[3, 2, np.nan, 1], [2, np.nan, 4, 5], [1, 6, 3, 2], [np.nan, 5, 6, 1]], index=['a', 'b', 'c', 'd'], columns=['one', 'two', 'three', 'four'])
# 判断df中每个位置是否为缺失值
print(df.isnull())
# 运行结果
one two three four
a False False True False
b False True False False
c False False False False
d True False False False
# 使用结合any函数对原DataFrame进行切片,提取所有包含缺失值的数据
print(df[df.isnull().any(axis=1)])
# 运行结果
one two three four
a 3.0 2.0 NaN 1
b 2.0 NaN 4.0 5
d NaN 5.0 6.0 1
(2)过滤缺失值
# 使用dropna函数过滤缺失值,返回不含缺失值的数据和索引
arr = pd.Series([1, 2, 3, np.nan, 5, 6])
print("arr: {}".format(arr))
# 过滤缺失值
print("过滤缺失值: {}".format(arr.dropna())) # inplace默认值是False,指不改动原数据,inplace=True指在原数据上过滤掉空值
# print("过滤缺失值: {}".format(arr.dropna(inplace=True)))
# 运行结果
arr: 0 1.0
1 2.0
2 3.0
3 NaN
4 5.0
5 6.0
dtype: float64
过滤缺失值: 0 1.0
1 2.0
2 3.0
4 5.0
5 6.0
dtype: float64
# 过滤DataFrame中的空值
df = pd.DataFrame([[3, 2, np.nan, 1], [2, np.nan, 4, 5], [1, 6, 3, 2], [np.nan, 5, 6, 1]], index=['a', 'b', 'c', 'd'], columns=['one', 'two', 'three', 'four'])
print(df)
print("df过滤空值: {}".format(df.dropna(inplace=True)))
# 运行结果
one two three four
a 3.0 2.0 NaN 1
b 2.0 NaN 4.0 5
c 1.0 6.0 3.0 2
d NaN 5.0 6.0 1
df过滤空值: one two three four
c 1.0 6.0 3.0 2
df = pd.DataFrame([[3, 2, np.nan, 1, np.nan], [2, np.nan, 4, 5, np.nan], [1, 6, 3, 2, np.nan], [np.nan, 5, 6, 1, np.nan]], index=['a', 'b', 'c', 'd'], columns=['one', 'two', 'three', 'four', 'fifth'])
print(df)
print("df过滤空值: {}".format(df.dropna(how='all', axist=1)))
one two three four fifth
a 3.0 2.0 NaN 1 NaN
b 2.0 NaN 4.0 5 NaN
c 1.0 6.0 3.0 2 NaN
d NaN 5.0 6.0 1 NaN
df过滤空值: one two three four
a 3.0 2.0 NaN 1
b 2.0 NaN 4.0 5
c 1.0 6.0 3.0 2
d NaN 5.0 6.0 1
(3)填充缺失值
df = pd.DataFrame([[3, 2, np.nan, 1, np.nan], [2, np.nan, 4, 5, np.nan], [1, 6, 3, 2, np.nan], [np.nan, 5, 6, 1, np.nan]], index=['a', 'b', 'c', 'd'], columns=['one', 'two', 'three', 'four', 'fifth'])
# 使用fillna函数填充传入的数值
print("用0填充df: {}".format(df.fillna(0)))
# 运行结果
用0填充df: one two three four fifth
a 3.0 2.0 0.0 1 0.0
b 2.0 0.0 4.0 5 0.0
c 1.0 6.0 3.0 2 0.0
d 0.0 5.0 6.0 1 0.0
# 数据分析中常用的填充数值是数据当前列的中位数或者均值
# 使用中位数填充缺失值
print("用中位数填充后的df: {}".format(df.fillna(df.median())))
# 运行结果
用中位数填充后的df: one two three four fifth
a 3.0 2.0 4.0 1 NaN
b 2.0 5.0 4.0 5 NaN
c 1.0 6.0 3.0 2 NaN
d 2.0 5.0 6.0 1 NaN
# 向上填充,使用缺失值的前一个数据替代缺失值
print("使用向上填充后的df: {}".format(df.ffill()))
# 向下填充,使用缺失值的后一个数据替代缺失值
print("使用向下填充后的df: {}".format(df.bfill()))
# 运行结果
使用向上填充后的df: one two three four fifth
a 3.0 2.0 NaN 1 NaN
b 2.0 2.0 4.0 5 NaN
c 1.0 6.0 3.0 2 NaN
d 1.0 5.0 6.0 1 NaN
使用向下填充后的df: one two three four fifth
a 3.0 2.0 4.0 1 NaN
b 2.0 6.0 4.0 5 NaN
c 1.0 6.0 3.0 2 NaN
d NaN 5.0 6.0 1 NaN
2. 重复值处理
DataFrame中可能存在重复行或列,或者几行中存在重复的几列,数据的重复和冗余可能会影响数据分析的准确性。
(1)查看DataFrame中的重复值
df = pd.DataFrame([[3,5,3,1],[2,5,5,6],[3,4,5,3],[5,3,1,3],[3,4,5,3],[3,4,6,8],[3,4,5,3]], index=['a','b','c','d','e','f','g'], columns=['one','two','three','four'])
# 查看是否存在重复行
print(df[df.duplicated()])
# 查看是否存在前两列重复的行
print(df[df.duplicated(subset=['one','two'])])
# 运行结果
one two three four
e 3 4 5 3 # duplicated默认保留第一次出现重复值的行,输出后面重复的行
g 3 4 5 3
one two three four
e 3 4 5 3
f 3 4 6 8
g 3 4 5 3
(2)去除DataFrame中的重复值
# 删除重复列,保留第一次出现的重复行
print(df.drop_duplicates(subset=['one', 'two'], keep='first')) keep的参数还可用'last'和'False' 分别表示保留最后一次出现的重复值、去除所有的重复值行
# 运行结果
one two three four
a 3 5 3 1
b 2 5 5 6
c 3 4 5 3
d 5 3 1 3
(3)数据记录合并与分组
- 使用append函数合并数据记录,对于两个列索引完全相同的DataFrame,可以用appen函数对二者进行上下合并
df1 = pd.DataFrame([[3,5,3,1],[2,5,5,6],[3,4,5,3],[5,3,1,3],[3,4,5,3],[3,4,6,8],[3,4,5,3]], index=['a','b','c','d','e','f','g'], columns=['one','two','three','four'])
df2 = pd.DataFrame([[3,3,2,4],[5,4,3,2]], index=['h','i'], columns=['one','two','three','four'])
# 输出合并之后的DataFrame
print(df1.append(df2))
print(df2.append(df1))
# 运行结果
one two three four
a 3 5 3 1
b 2 5 5 6
c 3 4 5 3
d 5 3 1 3
e 3 4 5 3
f 3 4 6 8
g 3 4 5 3
h 3 3 2 4
i 5 4 3 2
one two three four
h 3 3 2 4
i 5 4 3 2
a 3 5 3 1
b 2 5 5 6
c 3 4 5 3
d 5 3 1 3
e 3 4 5 3
f 3 4 6 8
g 3 4 5 3
- 使用concat函数合并数据记录,concat函数可以指定两个DataFrame按某个轴进行连接,也可以指定二者连接的方式。axis参数可以指定连接的轴向,axis默认值为0,表示列对齐,两表上下合并,与append()结果相同;axis=1时,表示行对齐,两表左右合并
# df1与df2上下连接
print(pd.concat([df1,df2]))
# 运行结果
one two three four
a 3 5 3 1
b 2 5 5 6
c 3 4 5 3
d 5 3 1 3
e 3 4 5 3
f 3 4 6 8
g 3 4 5 3
h 3 3 2 4
i 5 4 3 2
# df1与df2左右连接
print(pd.concat([df1,df2],axis=1))
# 运行结果
one two three four one two three four
a 3.0 5.0 3.0 1.0 NaN NaN NaN NaN
b 2.0 5.0 5.0 6.0 NaN NaN NaN NaN
c 3.0 4.0 5.0 3.0 NaN NaN NaN NaN
d 5.0 3.0 1.0 3.0 NaN NaN NaN NaN
e 3.0 4.0 5.0 3.0 NaN NaN NaN NaN
f 3.0 4.0 6.0 8.0 NaN NaN NaN NaN
g 3.0 4.0 5.0 3.0 NaN NaN NaN NaN
h NaN NaN NaN NaN 3.0 3.0 2.0 4.0
i NaN NaN NaN NaN 5.0 4.0 3.0 2.0
# df1与df2左右连接,join='outer' ,表示两数据集存在不重合索引,则取并集,未匹配的位置记录为NaN,join='inner'表示对两数据集取交集,只但会两数据集都匹配成功的数据
print(pd.concat([df1,df2],axis=1,join='outer'))
- 使用merge函数合并数据记录,merge函数可以根据两个DataFrame共有的某个字段进行数据合并,类似于关系数据库的连接,通过一个或多个键将两个数据集的行连接在一起。合并后的DataFrame行数没有增加,列数为两个DataFrame的总列数减去连接键的数量。
# 创建两个数据集
df_dic1 = {
'color':['red','yellow','blue','purple','pink'],
'size':['meidum','small','big','medium','small'],
'taste':['sweet','sour','salty','sweet','spicy'],
'category':[2,3,4,5,6]
}
df1 = pd.DataFrame(df_dic1, columns=['taste','color','size','category'])
print(df1)
df_dic2 = {
'country':['China', 'UK', 'USA', 'Australia', 'Japan'],
'quality':['good','normal','excellent','good','bad'],
'category':[2,3,5,6,7]
}
df2 = pd.DataFrame(df_dic2, columns=['country','quality','category'])
print(df2)
# 运行结果
taste color size category
0 sweet red meidum 2
1 sour yellow small 3
2 salty blue big 4
3 sweet purple medium 5
4 spicy pink small 6
country quality category
0 China good 2
1 UK normal 3
2 USA excellent 5
3 Australia good 6
4 Japan bad 7
# 使用merge函数合并两个数据集
print(pd.merge(df1,df2,left_on='category', right_on='category', how='left')) # left_on、right_on指明两个数据表中哪一个是用于连接的主键,名称可以不同。 how参数表示DataFrame的连接方式,默认为‘inner’,表示根据主键对两表匹配时,若未完全匹配,则保留匹配成功的部分,也就是两者的交集。how的参数的值还可能为‘left’、‘right’、‘outer’。how的参数为‘outer’时,两个DataFrame中为匹配成功的部分全部保留,也就是取二者的并集。how的参数设为‘left’值时,两个DataFrame中未匹配的部分保留左边DataFrame中含有,但是DataFrame中并不含有的部分,与之相反的是how=‘right’时保留右边DataFrame中含有,但左边DataFrame中不含有的部分。
# 运行结果,保左边
taste color size category country quality
0 sweet red meidum 2 China good
1 sour yellow small 3 UK normal
2 salty blue big 4 NaN NaN
3 sweet purple medium 5 USA excellent
4 spicy pink small 6 Australia good
print(pd.merge(df1,df2,left_on='category', right_on='category', how='right'))
# 运行结果,保右边
taste color size category country quality
0 sweet red meidum 2 China good
1 sour yellow small 3 UK normal
2 sweet purple medium 5 USA excellent
3 spicy pink small 6 Australia good
4 NaN NaN NaN 7 Japan bad
print(pd.merge(df1,df2,left_on='category', right_on='category', how='inner'))
# 运行结果,取交集
taste color size category country quality
0 sweet red meidum 2 China good
1 sour yellow small 3 UK normal
2 sweet purple medium 5 USA excellent
3 spicy pink small 6 Australia good
print(pd.merge(df1,df2,left_on='category', right_on='category', how='outer'))
# 运行结果,取并集
taste color size category country quality
0 sweet red meidum 2 China good
1 sour yellow small 3 UK normal
2 salty blue big 4 NaN NaN
3 sweet purple medium 5 USA excellent
4 spicy pink small 6 Australia good
5 NaN NaN NaN 7 Japan bad
十三、Python数据可视化
13.1 Matplotlib绘图
Matplotlib是Python数据可视化中应用最广泛的绘图库之一,它是一个类似于Matlab的绘图库,提供了一套与Matlab相似的命令API,适合交互式绘图。Matplotlib也可以作为绘图控件嵌入到GUI应用程序中。Matplotlib中的绘图函数位于matplotlib.pyplot模块中。
# 引入matplotlib
import matplotlib.pyplot as plt
13.1.1 初试Matplotlib
1.绘制简单图形
# 绘制sin函数曲线
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x = np.arange(0,6,0.1)
y1 = np.sin(x)
y2 = np.cos(x)
# 绘制图形
plt.plot(x,y1,label="sinx")
plt.plot(x,y2,label="cosx",linestyle="-.")
plt.xlabel("x") # x轴标签
plt.ylabel("y") # y轴标签
plt.title("sinx & cosx") # 标题
plt.legend()
plt.show()
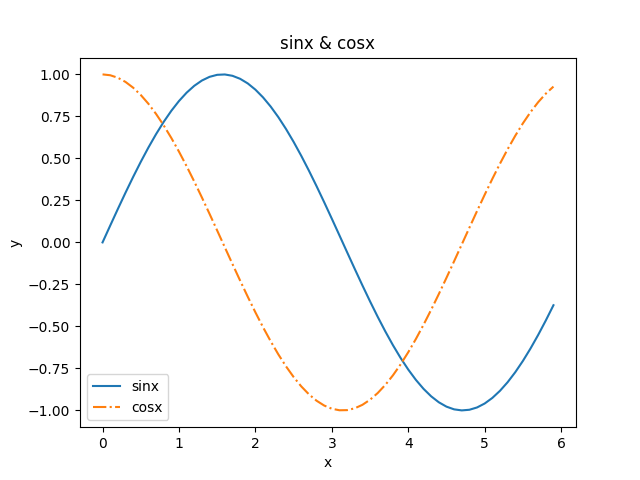
2.显示图形
pyplot中提供了用于显示图像的方法imshow()。另外,还可用使用matplotlib.image模块的imread()读入图像。
import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread("myplot.png")
plt.imshow(img)
plt.show()
13.1.2 绘制散点图
散点图可以直接醒目地反映数据的分布形态以及变量间的统计关系,matplotlib库1中的scatter函数可用于绘制散点图。
1.绘制简单的散点图
# 使用scatter函数绘制简单的散点图
from matplotlib import pyplot as plt
import numpy as np
# np.random.randn返回一个符合标准正态分布的数组
x = np.random.randn(1000)
y = np.random.randn(1000)
plt.scatter(x,y)
plt.title("Scatter plot for 1000 random data from normal distribution")
plt.show()
title()参数:
- fontsize: 标题文本字体大小
- fontweight: 标题文本粗细
- coclor:标题字体颜色
- loc:标题位置
scatter(x, y, s=None, c=None, marker=None, alpha=None)参数:
- s:表示数据标志(图纸表示数值点的圆点)的大小,s的取值的大小与数据标志的面积成正比,默认的s值为20,可根据图表可视化需求对其进行调整。s参数可以是一个数,此时统一调整所有的数据标志大小,也可以是一个与原数据数组形状相同的数组,此时数组的每个位置与原数组元素对应,分别对每一个数标志的大小做调整。
- c:表示数据标志的颜色,默认为蓝色,c参数可以是一个数值也可以是一维数组,为图中的数据标志指定相应的颜色数值。
常见颜色参数:
| 设置方式 | 颜色 | 设置方式 | 颜色 |
|---|---|---|---|
| c='r' | red | c='k' | black |
| c='g' | green | c='y' | yellow |
- marker:表示数据标志的形状,默认为圆,marker参数的取值可以是表示形状的字符串,也可以是表示多边形的包含两个元素的元组,第一个元素表示多边形边数;第二个元素记录多边形的样式,取值范围为0、1、2、3,0表示多边形,1表示星形,2表示放射形,3表示忽略边数显示为圆形。
常用的marker形状如下所示:
| marker | 形状 | marker | 形状 |
|---|---|---|---|
| "." | 点 | "s" | 方形 |
| "o" | 圆圈 | "p" | 五边形 |
| "v" | 向下的三角形 | "*" | 星形 |
| "^" | 向上的三角形 | "D" | 菱形 |
| "<" | 向左的三角形 | "+" | 加号 |
| ">" | 向右的三角形 | "x" | 叉号 |
- alpha:表示描述数据标志的透明度,0表示透明,1表示不透明,可选择0到1之间的任意数,透明度根据0到1的取值递减。
2.绘制复杂的散点图
# 使用scatter函数绘制星形散点图
x = np.random.randn(1000)
y = np.random.randn(1000)
plt.scatter(x,y,color="g",marker='*',alpha=0.5)
plt.title("Scatter plot for 1000 random data from normal distribution")
plt.show()
# 调整坐标轴的范围
x = np.random.randn(1000)
y = np.random.randn(1000)
plt.scatter(x,y,color="g",marker='*',alpha=0.5)
plt.title("Scatter plot for 1000 random data from normal distribution")
# 调整x轴范围
plt.xlim(-5,5)
# 调整y轴范围
plt.ylim(-5,5)
plt.show()
# 调整坐标轴的范围
x = np.random.randn(1000)
y = np.random.randn(1000)
plt.scatter(x,y,color="g",marker='*',alpha=0.5)
plt.title("Scatter plot for 1000 random data from normal distribution")
# 调整x轴范围
plt.xlim(-5,5)
# 调整y轴范围
plt.ylim(-5,5)
plt.show()
13.1.3 绘制折线图
折线图可以显示随着时间变化的连续数据,适合描述相等时间间隔下数据的变化趋势。Matplotlib库中的plot函数可用于绘制折线图。
import numpy as np
import matplotlib.pyplot as plt
x1 = np.arange(10)
y1 = np.random.randn(10)
x2 = np.arange(10)
y2 = np.random.randn(10)
# linestyle :supported values are '-', '--', '-.', ':', 'None', ' ', '', 'solid', 'dashed', 'dashdot', 'dotted'
plt.plot(x1,y1,color="r",label="random_y1",linestyle="--")
plt.plot(x2,y2,color="pink",label="random_y2",linestyle="--")
plt.title("random number")
# 设置坐标轴名称
plt.xlabel("x轴")
plt.ylabel("y轴")
plt.legend() # 注意要在plt.show()前加,这样才可以在图像中显示图例
plt.show()
13.1.4 绘制柱状图
柱状图是以高度不等的长方形的长度来表示数据的分布,易于比较各组数据之间的差别。Matplotlib库中可以使用bar函数来绘制柱状图。
import numpy as np
from matplotlib import pyplot as plt
index = np.arange(5)
value = [20, 30, 45, 35, 50]
# facecolor: 柱状图填充颜色 label:图例的解释
plt.bar(index, value, width=0.5, label='high', facecolor='green')
plt.title("test bar")
# 刻度(刻标[轴上的位置],刻度标签[刻度上的信息])
plt.xticks(index, ['group1', 'group2', 'group3', 'group4', 'group5'])
plt.yticks(np.arange(0, 60, 10))
# 显示图例
plt.legend(loc='upper left')
# 将数据打包成元组
a = zip(index, value)
for x, y in a:
# 前两个参数指定x和y坐标,第三个参数为添加的标签内容,ha:h-horizontal表示按行对齐 va:v-vertical表示按照列对齐
plt.text(x, y, y, ha='center', va='bottom')
plt.show()
import numpy as np
from matplotlib import pyplot as plt
import matplotlib
print(matplotlib.__version__)
index = np.arange(5)
value = [20, 30, 45, 35, 50]
# facecolor: 柱状图填充颜色 label:图例的解释
plt.bar(index, value, width=0.5, label='high', facecolor='green')
plt.title("test bar")
# 刻度(刻标[轴上的位置],刻度标签[刻度上的信息])
plt.xticks(index, ['group1', 'group2', 'group3', 'group4', 'group5'])
plt.yticks(np.arange(0, 60, 10))
# 显示图例
plt.legend(loc='upper left')
# 将数据打包成元组
a = zip(index, value)
for x, y in a:
# 前两个参数显示x和y轴坐标,第三个参数显示每个柱子上的数值,ha:h-horizontal表示按行对齐,va:v_vertical表示按列对齐
plt.text(x, y, y, ha='center', va='bottom')
plt.show()
13.1.5 绘制箱线图
箱线图是一种用来描述数据分散情况的统计图,可进行多组数据比较。箱线图的构造如下图所示:
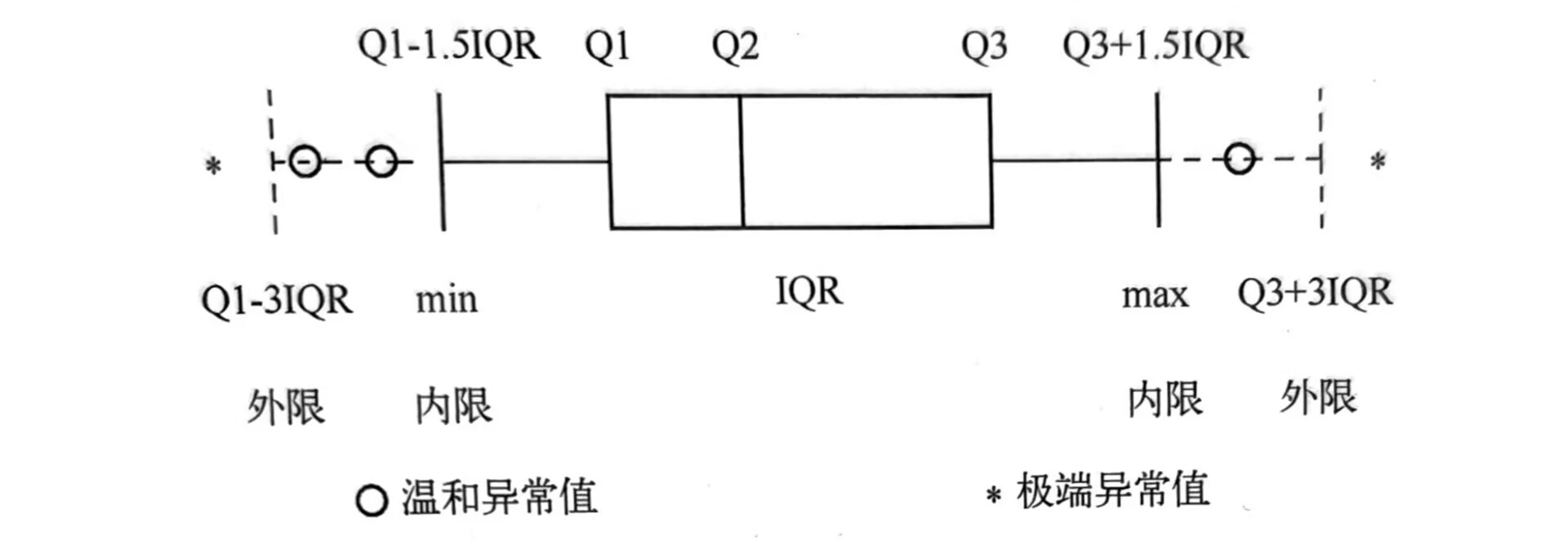
在箱线图中,矩形盒两端的位置分别对应数据的上下四分位数,也就是Q1和Q3,所以矩形盒的长度Q3-Q1也叫做四分位距,或者四分位差,用IQR表示。在数据分析中,往往会重点考虑数据列中中间部分的数字,通常会将前25%和后25%的数据切掉,保留从Q1到Q3之间的数据。
矩形盒内部的线段表示中位数Q2。
从矩形盒的两端伸出两条线,线的端点分别为Q1-1.5IQR和Q3+1.5IQR,这两个端点叫做异常值极端点,称其为内限。
落在内限之外的点为数据的异常值,所以这两个端点也表示在不考虑异常值的情况下数据的最大值和最小值。
Q1-3IQR和Q3+3IQR处的两个端点称为外限,落在内限和外限之间的点被称作温和异常值,外限之外的异常值叫作极端异常值。
箱线图可以直观明了地识别数据中的异常值,并且在不受异常值的影响下以一种相对稳定的方式描述数据的离散分布情况。在数据分析的过程中,忽视异常值是很危险的,如果不加剔除地将异常值包括在数据分析中,可能会对结果产生不良的影响。重视异常值,对发现问题、提出改进策略有很大的帮助,同时也有利于数据的清洗。
# 使用Matplotlib库中的boxplot函数绘制箱线图
import numpy as np
import matplotlib.pyplot as plt
arr1 = np.random.randint(0, 100,10)
arr2 = np.random.randint(10, 110,10)
print(arr1.shape)
plt.boxplot((arr1, arr2), labels=["arr1", "arr2"])
plt.title = ("test boxplot")
plt.show()
评论区